Publications
An updated list of publications can be found in my Google Scholar profile.
2026
- arXiv26
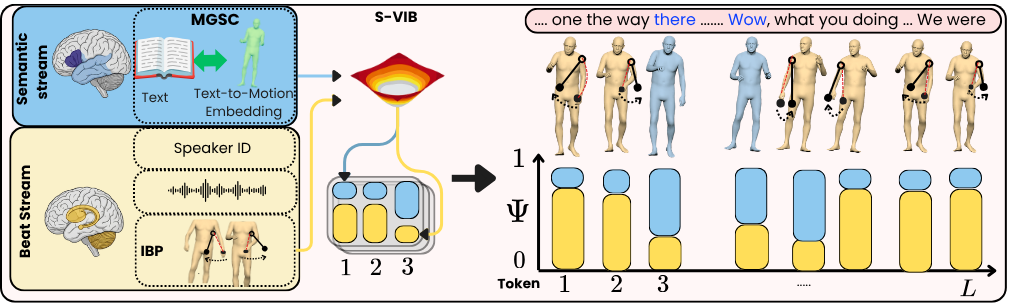 DuoGesture: Neuro-Inspired and Biomechanically Informed Dual-Stream Co-Speech Gesture GenerationFerdinand Paar, Lanmiao Liu, Aslı Özyürek, and 2 more authorsarXiv preprint arXiv:2605.26236, May 2026
DuoGesture: Neuro-Inspired and Biomechanically Informed Dual-Stream Co-Speech Gesture GenerationFerdinand Paar, Lanmiao Liu, Aslı Özyürek, and 2 more authorsarXiv preprint arXiv:2605.26236, May 2026Co-speech gesture generation requires both semantic expressivity and biomechanically plausible rhythmic motion. Existing holistic gesture models mix lexically grounded semantic gestures with frequent prosody-aligned beat gestures. This limits semantic grounding, speech-motion alignment, and kinematic smoothness. We propose DuoGesture, a neuro-inspired and biomechanically informed dual-stream approach that decomposes co-speech gesture synthesis into coupled semantic and beat streams. The two streams are coordinated by a Semantic Variational Information Bottleneck, a stochastic frame-level gate that learns when semantic gestures should override rhythmic beat motion. The semantic stream is controlled by Motion-Grounded Semantic Conditioning, which replaces purely linguistic word embeddings with motion-language representations to provide motion-aligned semantic priors for long-tailed lexical triggers of gestures. The beat stream is further regularised by an Inertial Beat Prior, an anthropometry-weighted arm-chain module that reduces jitter and improves rhythmic consistency without constraining semantic frames. Objective evaluations and subjective experiments show that DuoGesture outperforms strong holistic baselines, while component ablations confirm the complementary roles of semantic grounding, stochastic stream selection, and biomechanical regularisation.
@article{paar2026duogesture, title = {DuoGesture: Neuro-Inspired and Biomechanically Informed Dual-Stream Co-Speech Gesture Generation}, author = {Paar, Ferdinand and Liu, Lanmiao and {\"O}zy{\"u}rek, Asl{\i} and Thill, Serge and Ghaleb, Esam}, journal = {arXiv preprint arXiv:2605.26236}, year = {2026}, month = may, publisher = {arXiv}, url = {https://arxiv.org/abs/2605.26236}, keywords = {Co-speech gesture generation, semantic grounding, beat gestures, biomechanical regularisation, multimodal learning, gesture synthesis}, } - arXiv26
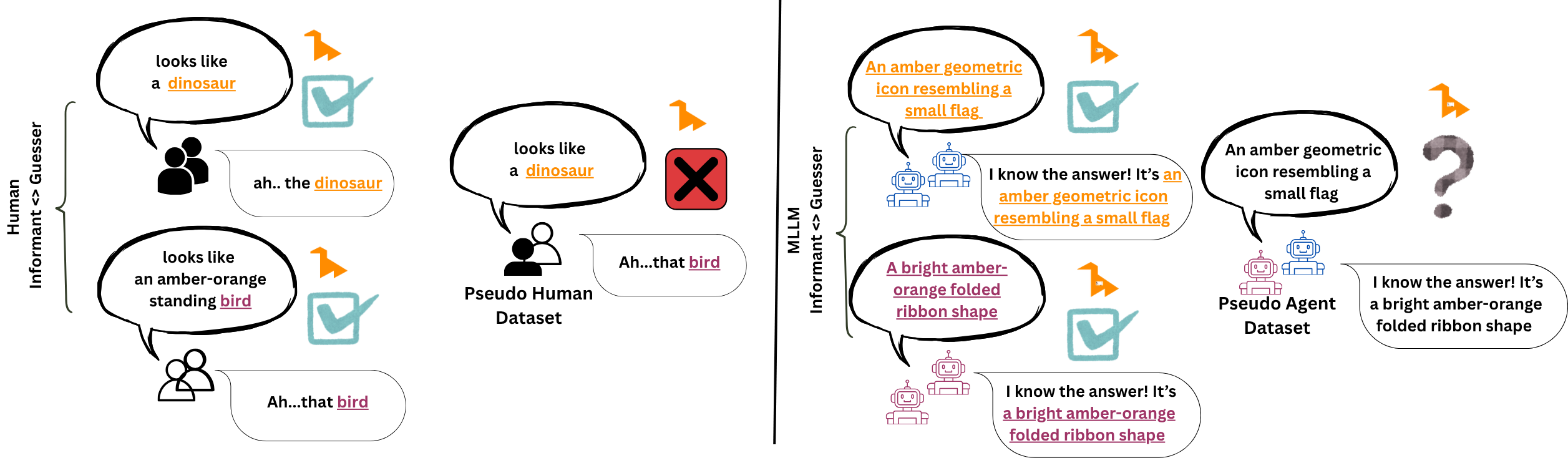 Aligned but Not Partner-Specific: Distinguishing How Multimodal LLM Agents Succeed in Reference Games Without Human-Like ConventionsPo-Ya Angela Wang, Chinmaya Mishra, Aslı Özyürek, and 2 more authorsarXiv preprint arXiv:2606.08081, Jun 2026
Aligned but Not Partner-Specific: Distinguishing How Multimodal LLM Agents Succeed in Reference Games Without Human-Like ConventionsPo-Ya Angela Wang, Chinmaya Mishra, Aslı Özyürek, and 2 more authorsarXiv preprint arXiv:2606.08081, Jun 2026Repeated reference games test whether interlocutors replace their initially long descriptions with shorter, partner-specific conventions grounded in shared interaction history. Prior work shows that multimodal LLMs fail to become more efficient across rounds, although they align on the labels they use. How can we determine whether this alignment reflects partner-specific grounding rather than a shared task vocabulary? We address this question by comparing capable multimodal agent dyads with human dyads from the KTH Tangrams corpus. Our novel methodological contribution is a constrained pseudo-dyad baseline that matches the original referential task structure, but breaks partner history. This baseline enables us to test whether the observed label alignment depends on interaction with a specific partner. Across three analytic layers, task competence, description strategy, and alignment dynamics, we find clear differences. Humans reduce effort through entrainment, compressing descriptions and increasing label alignment with partners. Agents instead maintain fixed effort levels, producing verbose descriptions from round one, with near-ceiling label overlap that is statistically indistinguishable between real and pseudo dyads. MLLMs thus achieve coordination without convention, succeeding by verbose description rather than by forming the compact, history-dependent referring expressions characteristic of human dialogue.
@article{wang2026aligned, title = {Aligned but Not Partner-Specific: Distinguishing How Multimodal LLM Agents Succeed in Reference Games Without Human-Like Conventions}, author = {Wang, Po-Ya Angela and Mishra, Chinmaya and {\"O}zy{\"u}rek, Asl{\i} and Rubio-Fern{\'a}ndez, Paula and Ghaleb, Esam}, journal = {arXiv preprint arXiv:2606.08081}, year = {2026}, month = jun, publisher = {arXiv}, url = {https://arxiv.org/abs/2606.08081}, keywords = {Multimodal LLM agents, reference games, partner-specific conventions, dialogue alignment, common ground, human-agent comparison}, } - ECCV26
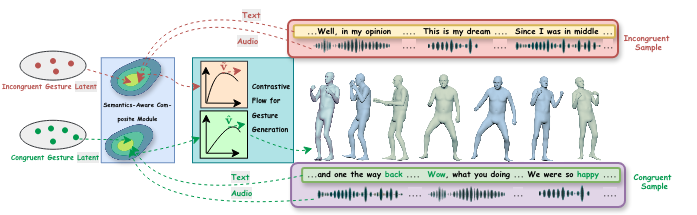 SemConFlow: Semantic Grounding of Holistic Co-Speech Gesture Generation with Contrastive Flow-MatchingLanmiao Liu, Esam Ghaleb, Aslı Özyürek, and 1 more authorEuropean Conference on Computer Vision (ECCV), Mar 2026
SemConFlow: Semantic Grounding of Holistic Co-Speech Gesture Generation with Contrastive Flow-MatchingLanmiao Liu, Esam Ghaleb, Aslı Özyürek, and 1 more authorEuropean Conference on Computer Vision (ECCV), Mar 2026While the field of co-speech gesture generation has seen significant advances, producing holistic, semantically grounded gestures remains a challenge. Existing approaches rely on external semantic retrieval methods, which limit their generalisation capability due to dependency on predefined linguistic rules. Flow-matching-based methods produce promising results; however, the network is optimised using only semantically congruent samples without exposure to negative examples, leading to learning rhythmic gestures rather than sparse motion, such as iconic and metaphoric gestures. Furthermore, by modelling body parts in isolation, the majority of methods fail to maintain cross-modal consistency. We introduce a Contrastive Flow Matching-based co-speech gesture generation model that uses mismatched audio–text conditions as negatives, training the velocity field to follow the correct motion trajectory while repelling semantically incongruent trajectories. Our model ensures cross-modal coherence by embedding text, audio, and holistic motion into a composite latent space via cosine and contrastive objectives. Extensive experiments and a user study demonstrate that our proposed approach outperforms state-of-the-art methods on two datasets, BEAT2 and SHOW.
@article{liu2026semconflow, title = {SemConFlow: Semantic Grounding of Holistic Co-Speech Gesture Generation with Contrastive Flow-Matching}, author = {Liu, Lanmiao and Ghaleb, Esam and {\"O}zy{\"u}rek, Asl{\i} and Yumak, Zerrin}, journal = {European Conference on Computer Vision (ECCV)}, year = {2026}, month = mar, publisher = {IEEE/CVF}, url = {https://arxiv.org/abs/2603.26553}, keywords = {Co-speech gesture generation, semantic grounding, flow matching, contrastive learning, multimodal learning, gesture synthesis}, } - ACL26
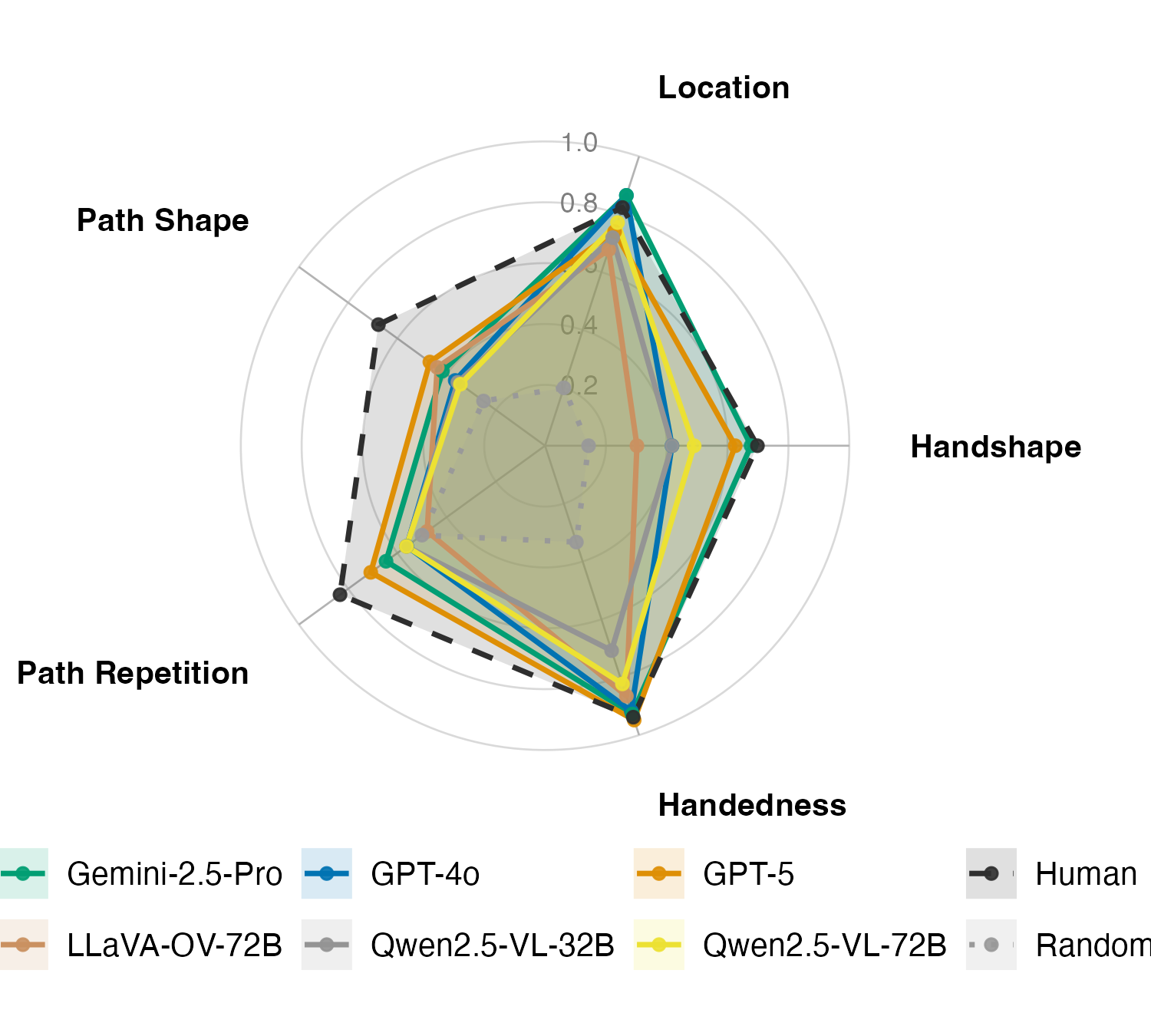 The Visual Iconicity Challenge: Evaluating Vision-Language Models on Sign Language Form-Meaning MappingOnur Keleş, Aslı Özyürek, Gerardo Ortega, and 2 more authorsIn Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL), San Diego, California, USA, Jul 2026
The Visual Iconicity Challenge: Evaluating Vision-Language Models on Sign Language Form-Meaning MappingOnur Keleş, Aslı Özyürek, Gerardo Ortega, and 2 more authorsIn Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL), San Diego, California, USA, Jul 2026Iconicity, the resemblance between linguistic form and meaning, is pervasive in signed languages, offering a natural testbed for visual grounding. For vision-language models (VLMs), the challenge is to recover such essential mappings from dynamic human motion rather than static context. We introduce the Visual Iconicity Challenge, a novel video-based benchmark that adapts psycholinguistic measures to evaluate VLMs on three tasks: (i) phonological sign-form prediction (e.g., handshape, location), (ii) transparency (inferring meaning from visual form), and (iii) graded iconicity ratings. We assess 13 state-of-the-art VLMs in zero- and few-shot settings on Sign Language of the Netherlands and compare them to human baselines. On phonological form prediction, VLMs recover some handshape and location detail but remain below human performance; on transparency, they are far from human baselines; and only top models correlate moderately with human iconicity ratings. Interestingly, models with stronger phonological form prediction correlate better with human iconicity judgment, indicating shared sensitivity to visually grounded structure. Our findings validate these diagnostic tasks and motivate human-centric signals and embodied learning methods for modelling iconicity and improving visual grounding in multimodal models.
@inproceedings{keles2026visual, title = {The Visual Iconicity Challenge: Evaluating Vision-Language Models on Sign Language Form-Meaning Mapping}, author = {Keleş, Onur and {\"O}zy{\"u}rek, Asl{\i} and Ortega, Gerardo and G{\"o}kg{\"o}z, Kadir and Ghaleb, Esam}, booktitle = {Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL)}, year = {2026}, month = jul, location = {San Diego, California, USA}, publisher = {Association for Computational Linguistics}, url = {https://arxiv.org/abs/2510.08482}, keywords = {Vision-language models, sign language, iconicity, visual grounding, multimodal learning}, }
2025
- ICCV25
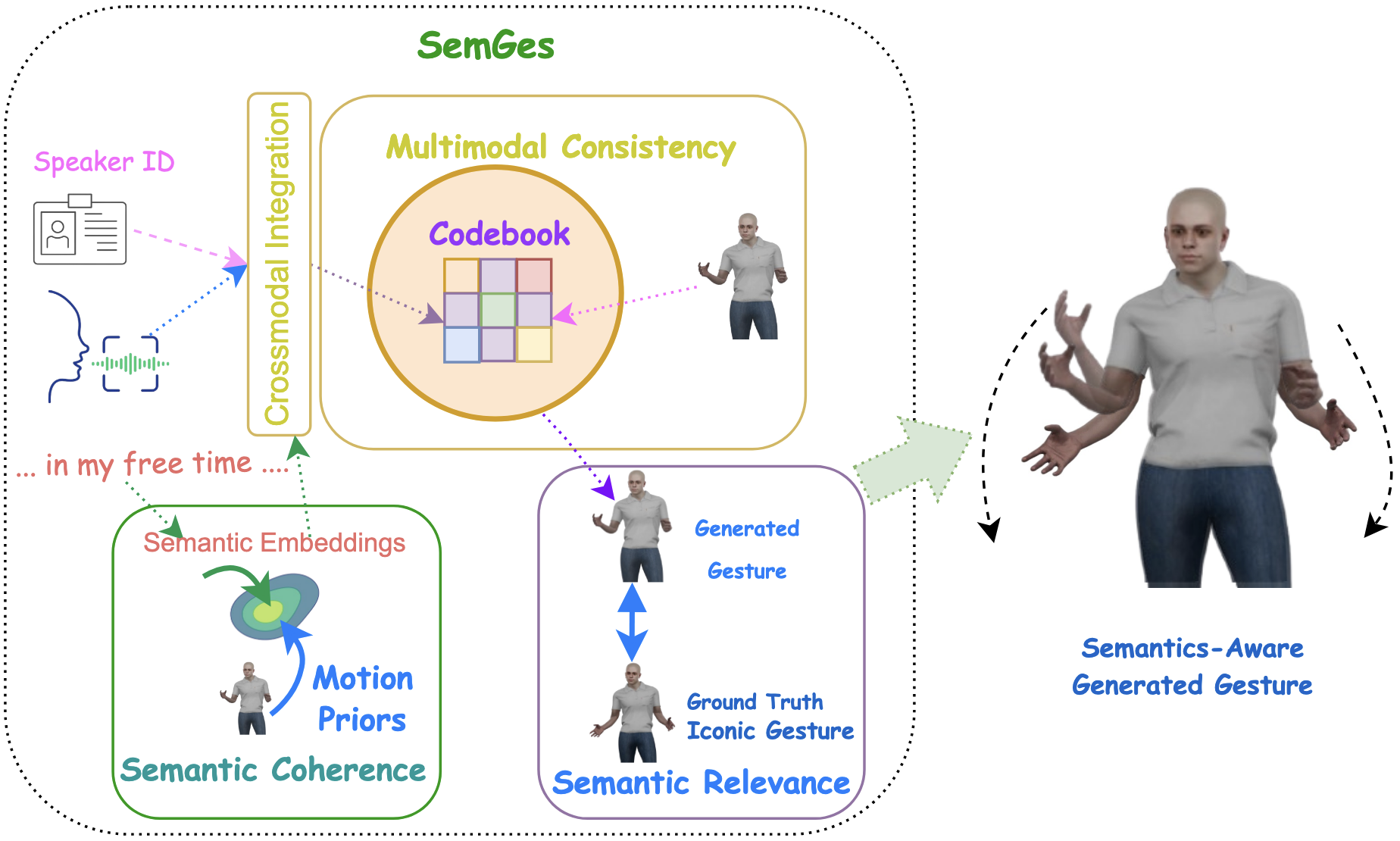 SemGes: Semantics-aware Co-Speech Gesture Generation using Semantic Coherence and Relevance LearningLanmiao Liu, Esam Ghaleb, Aslı Özyürek, and 1 more authorIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Honolulu, Hawai’i, USA, Oct 2025
SemGes: Semantics-aware Co-Speech Gesture Generation using Semantic Coherence and Relevance LearningLanmiao Liu, Esam Ghaleb, Aslı Özyürek, and 1 more authorIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Honolulu, Hawai’i, USA, Oct 2025Creating a virtual avatar with semantically coherent gestures that are aligned with speech is a challenging task. Existing gesture generation research mainly focused on generating rhythmic beat gestures, neglecting the semantic context of the gestures. In this paper, we propose a novel approach for semantic grounding in co-speech gesture generation that integrates semantic information at both fine-grained and global levels. Our approach starts with learning the motion prior through a vector-quantized variational autoencoder. Built on this model, a second-stage module is applied to automatically generate gestures from speech, text-based semantics and speaker identity that ensures consistency between the semantic relevance of generated gestures and co-occurring speech semantics through semantic coherence and relevance modules. Experimental results demonstrate that our approach enhances the realism and coherence of semantic gestures. Extensive experiments and user studies show that our method outperforms state-of-the-art approaches across two benchmarks in co-speech gesture generation in both objective and subjective metrics. The qualitative results of our model can be viewed at \hrefhttps://semgesture.github.io/https://semgesture.github.io/. Our code, dataset and pre-trained models will be shared upon acceptance.
@inproceedings{liu202SemGes, title = { SemGes: Semantics-aware Co-Speech Gesture Generation using Semantic Coherence and Relevance Learning }, author = {Liu, Lanmiao and Ghaleb, Esam and {\"O}zy{\"u}rek, Asl{\i} and Yumak, Zerrin}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, year = {2025}, month = oct, publisher = {CVF/IEEE}, address = {Honolulu, Hawai'i, USA}, url = {https://semgesture.github.io/}, numpages = {10}, keywords = {Gesture generation, semantics, generative AI}, location = {Honolulu, Hawai'i, USA}, series = {ICCV '25}, } - ACL25
 Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasksAnna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, and 8 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Vienna, Austria, Jul 2025
Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasksAnna Bavaresco, Raffaella Bernardi, Leonardo Bertolazzi, and 8 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Vienna, Austria, Jul 2025There is an increasing trend towards evaluating NLP models with LLMs instead of human judgments, raising questions about the validity of these evaluations, as well as their reproducibility in the case of proprietary models. We provide JudgeBench, an extensible collection of 20 NLP datasets with human annotations covering a broad range of evaluated properties and types of data, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show substantial variance across models and datasets. Models are reliable evaluators on some tasks, but overall display substantial variability depending on the property being evaluated, the expertise level of the human judges, and whether the language is human or model-generated. We conclude that LLMs should be carefully validated against human judgments before being used as evaluators.
@inproceedings{bavaresco2024llms, title = {Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasks}, author = {Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern{\'a}ndez, Raquel and Gatt, Albert and Ghaleb, Esam and Giulianelli, Mario and Hanna, Michael and Koller, Alexander and others}, year = {2025}, url = {https://arxiv.org/abs/2406.18403}, booktitle = {Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)}, month = jul, address = {Cedarville, Ohio, 45314, United States}, location = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url_github = {https://github.com/dmg-illc/JUDGE-BENCH}, } - ACL25
 I see what you mean: Co-Speech Gestures for Reference Resolution in Multimodal DialogueEsam Ghaleb, Bulat Khaertdinov, Aslı Özyürek, and 1 more authorIn Proceedings of the of the 63rd Conference of the Association for Computational Linguistics (ACL Findings), Veinna, Austria, Jul 2025
I see what you mean: Co-Speech Gestures for Reference Resolution in Multimodal DialogueEsam Ghaleb, Bulat Khaertdinov, Aslı Özyürek, and 1 more authorIn Proceedings of the of the 63rd Conference of the Association for Computational Linguistics (ACL Findings), Veinna, Austria, Jul 2025In face-to-face interaction, we use multiple modalities, including speech and gestures, to communicate information and resolve references to objects. However, how representational co-speech gestures refer to objects remains understudied from a computational perspective. In this work, we address this gap by introducing a multimodal reference resolution task centred on representational gestures, while simultaneously tackling the challenge of learning robust gesture embeddings. We propose a self-supervised pre-training approach to gesture representation learning that grounds body movements in spoken language. Our experiments show that the learned embeddings align with expert annotations and have significant predictive power. Moreover, reference resolution accuracy further improves when (1) using multimodal gesture representations, even when speech is unavailable at inference time, and (2) leveraging dialogue history. Overall, our findings highlight the complementary roles of gesture and speech in reference resolution, offering a step towards more naturalistic models of human-machine interaction.
@inproceedings{ghaleb-etal-acl-2025, author = {Ghaleb, Esam and Khaertdinov, Bulat and {\"O}zy{\"u}rek, Asl{\i} and Fern{\'a}ndez, Raquel}, title = {I see what you mean: Co-Speech Gestures for Reference Resolution in Multimodal Dialogue}, booktitle = {Proceedings of the of the 63rd Conference of the Association for Computational Linguistics (ACL Findings)}, publisher = {Association for Computational Linguistics}, address = {Cedarville, Ohio, 45314, United States}, month = jul, year = {2025}, location = {Veinna, Austria}, url = {https://arxiv.org/abs/2503.00071}, url_github = {https://github.com/EsamGhaleb/MultimodalReferenceResolution}, }
2024
- ICMI24
 Learning Co-Speech Gesture Representations in Dialogue through Contrastive Learning: An Intrinsic EvaluationEsam Ghaleb, Bulat Khaertdinov, Wim Pouw, and 4 more authorsIn International Conference on Multimodal Interaction, San Jose, Costa Rica, 2024
Learning Co-Speech Gesture Representations in Dialogue through Contrastive Learning: An Intrinsic EvaluationEsam Ghaleb, Bulat Khaertdinov, Wim Pouw, and 4 more authorsIn International Conference on Multimodal Interaction, San Jose, Costa Rica, 2024In face-to-face dialogues, the form-meaning relationship of co-speech gestures varies depending on contextual factors such as what the gestures refer to and the individual characteristics of speakers. These factors make co-speech gesture representation learning challenging. How can we learn meaningful gestures representations considering gestures’ variability and relationship with speech? This paper tackles this challenge by employing self-supervised contrastive learning techniques to learn gesture representations from skeletal and speech information. We propose an approach that includes both unimodal and multimodal pre-training to ground gesture representations in co-occurring speech. For training, we utilize a face-to-face dialogue dataset rich with representational iconic gestures. We conduct thorough intrinsic evaluations of the learned representations through comparison with human-annotated pairwise gesture similarity. Moreover, we perform a diagnostic probing analysis to assess the possibility of recovering interpretable gesture features from the learned representations. Our results show a significant positive correlation with human-annotated gesture similarity and reveal that the similarity between the learned representations is consistent with well-motivated patterns related to the dynamics of dialogue interaction. Moreover, our findings demonstrate that several features concerning the form of gestures can be recovered from the latent representations. Overall, this study shows that multimodal contrastive learning is a promising approach for learning gesture representations, which opens the door to using such representations in larger-scale gesture analysis studies.
@inproceedings{Ghaleb2024le, title = {Learning Co-Speech Gesture Representations in Dialogue through Contrastive Learning: An Intrinsic Evaluation}, author = {Ghaleb, Esam and Khaertdinov, Bulat and Pouw, Wim and Rasenberg, Marlou and Holler, Judith and {\"O}zy{\"u}rek, Asl{\i} and Fern{\'a}ndez, Raquel}, booktitle = {International Conference on Multimodal Interaction}, volume = {26}, number = {26}, year = {2024}, isbn = {9798400704628}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3678957.3685707}, doi = {10.1145/3678957.3685707}, pages = {274–283}, numpages = {10}, keywords = {Gesture analysis, diagnostic probing., face-to-face dialogue, intrinsic evaluation, representation learning}, location = {San Jose, Costa Rica}, series = {ICMI '24}, } - ArXiv
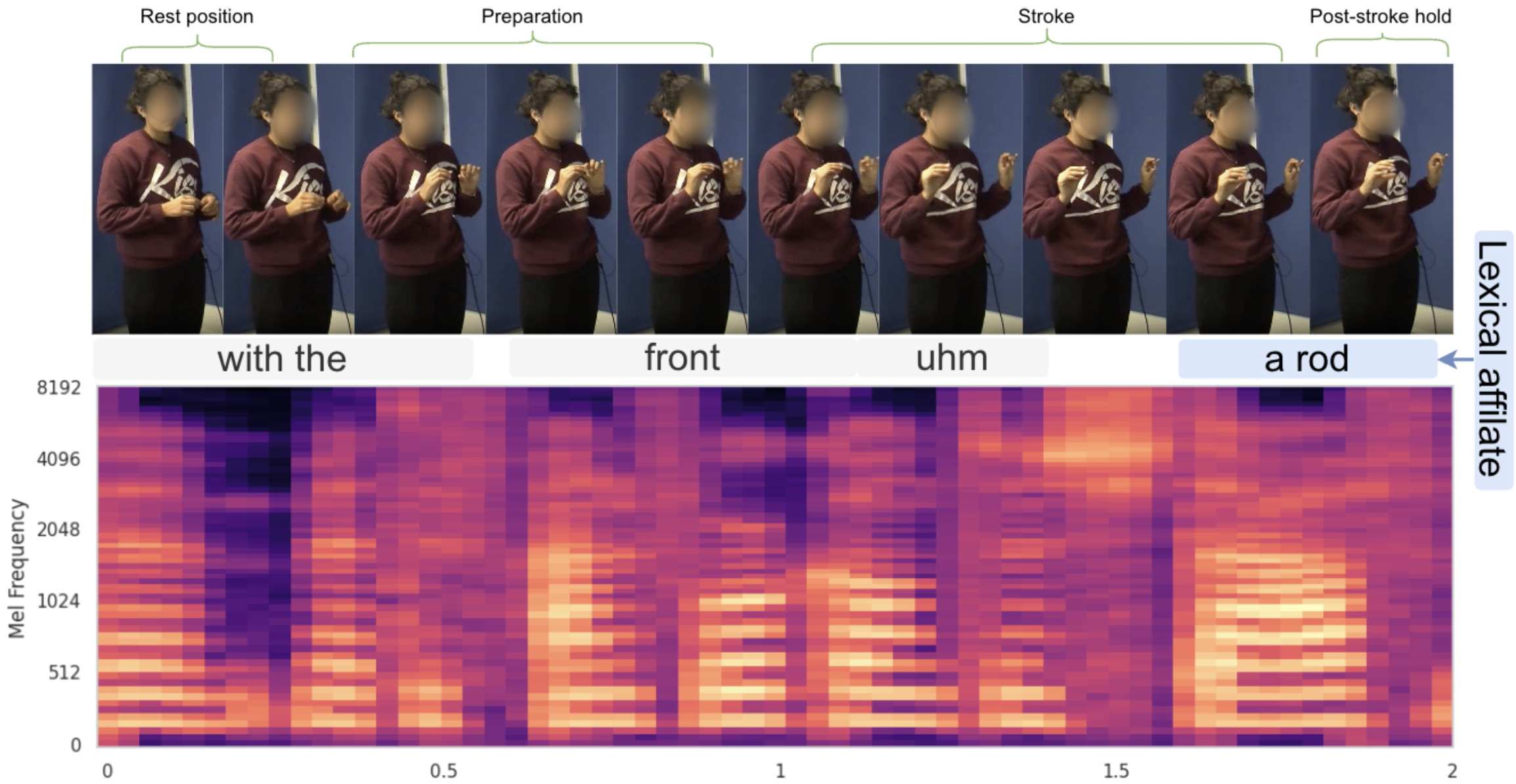 Leveraging Speech for Gesture Detection in Multimodal CommunicationEsam Ghaleb, Ilya Burenko, Marlou Rasenberg, and 7 more authorsarXiv preprint arXiv:2404.14952, 2024
Leveraging Speech for Gesture Detection in Multimodal CommunicationEsam Ghaleb, Ilya Burenko, Marlou Rasenberg, and 7 more authorsarXiv preprint arXiv:2404.14952, 2024Gestures are inherent to human interaction and often complement speech in face-to-face communication, forming a multimodal communication system. An important task in gesture analysis is detecting a gesture’s beginning and end. Research on automatic gesture detection has primarily focused on visual and kinematic information to detect a limited set of isolated or silent gestures with low variability, neglecting the integration of speech and vision signals to detect gestures that co-occur with speech. This work addresses this gap by focusing on co-speech gesture detection, emphasising the synchrony between speech and co-speech hand gestures. We address three main challenges: the variability of gesture forms, the temporal misalignment between gesture and speech onsets, and differences in sampling rate between modalities. Our approach leverages a sliding window technique to handle variability in gestures’ form and duration, using Mel-Spectrograms for acoustic speech signals and spatiotemporal graphs for visual skeletal data. We investigate extended speech time windows and employ separate backbone models for each modality to address the temporal misalignment and sampling rate differences. We utilize Transformer encoders in cross-modal and early fusion techniques to effectively align and integrate speech and skeletal sequences. The study results show that combining visual and speech information significantly enhances gesture detection performance. Our findings indicate that expanding the speech buffer beyond visual time segments improves performance and that multimodal integration using cross-modal and early fusion techniques outperforms baseline methods using unimodal and late fusion methods. Additionally, we find a correlation between the models’ gesture prediction confidence and low-level speech frequency features potentially associated with gestures. Overall, the study provides a better understanding and detection methods for co-speech gestures, facilitating the analysis of multimodal communication
@article{ghaleb2024leveraging, title = {Leveraging Speech for Gesture Detection in Multimodal Communication}, author = {Ghaleb, Esam and Burenko, Ilya and Rasenberg, Marlou and Pouw, Wim and Toni, Ivan and Uhrig, Peter and Wilson, Anna and Holler, Judith and {\"O}zy{\"u}rek, Asl{\i} and Fern{\'a}ndez, Raquel}, journal = {arXiv preprint arXiv:2404.14952}, year = {2024}, url = {https://arxiv.org/pdf/2404.14952.pdf}, pubstate = {pre-print}, } - CogSci24
 Speakers align both their gestures and words not only to establish but also to maintain reference to create shared labels for novel objects in interactionSho Akamine, Esam Ghaleb, Marlou Rasenberg, and 3 more authorsIn Proceedings of the Annual Meeting of the Cognitive Science Society, 2024
Speakers align both their gestures and words not only to establish but also to maintain reference to create shared labels for novel objects in interactionSho Akamine, Esam Ghaleb, Marlou Rasenberg, and 3 more authorsIn Proceedings of the Annual Meeting of the Cognitive Science Society, 2024When we communicate with others, we often repeat aspects of each other’s communicative behavior such as sentence structures and words. Such behavioral alignment has been mostly studied for speech or text. Yet, language use is mostly multimodal, flexibly using speech and gestures to convey messages. Here, we explore the use of alignment in speech (words) and co-speech gestures (iconic gestures) in a referential communication task aimed at finding labels for novel objects in interaction. In particular, we investigate how people flexibly use lexical and gestural alignment to create shared labels for novel objects and whether alignment in speech and gesture are related over time. The present study shows that interlocutors not only establish shared labels multimodally but also keep aligning in words and iconic gestures over the interaction. We also show that the amount of lexical alignment positively correlates with the amount of gestural alignment over time, suggesting a close relationship between alignment in the vocal and manual modalities.
@inproceedings{Akamine2024sp, title = {Speakers align both their gestures and words not only to establish but also to maintain reference to create shared labels for novel objects in interaction}, author = {Akamine, Sho and Ghaleb, Esam and Rasenberg, Marlou and Fern{\'a}ndez, Raquel and Meyer, Antje and {\"O}zy{\"u}rek, Asl{\i}}, booktitle = {Proceedings of the Annual Meeting of the Cognitive Science Society}, volume = {45}, number = {45}, year = {2024}, doi = {10.1145/3678957.3685707}, } - CogSci24
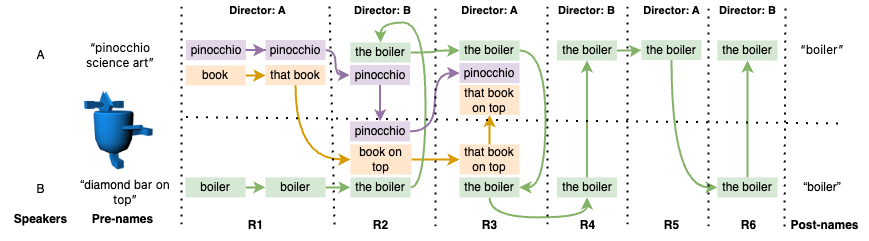 Analysing Cross-Speaker Convergence in Face-to-Face Dialogue through the Lens of Automatically Detected Shared Linguistic ConstructionsEsam Ghaleb, Marlou Rasenberg, Wim Pouw, and 4 more authorsIn Proceedings of the Annual Meeting of the Cognitive Science Society, 2024
Analysing Cross-Speaker Convergence in Face-to-Face Dialogue through the Lens of Automatically Detected Shared Linguistic ConstructionsEsam Ghaleb, Marlou Rasenberg, Wim Pouw, and 4 more authorsIn Proceedings of the Annual Meeting of the Cognitive Science Society, 2024Conversation requires a substantial amount of coordination between dialogue participants, from managing turn taking to negotiating mutual understanding. Part of this coordination effort surfaces as the reuse of linguistic behaviour across speakers, a process often referred to as \textitalignment. While the presence of linguistic alignment is well documented in the literature, several questions remain open, including the extent to which patterns of reuse across speakers have an impact on the emergence of labelling conventions for novel referents. In this study, we put forward a methodology for automatically detecting shared lemmatised constructions—expressions with a common lexical core used by both speakers within a dialogue—and apply it to a referential communication corpus where participants aim to identify novel objects for which no established labels exist. Our analyses uncover the usage patterns of shared constructions in interaction and reveal that features such as their frequency and the amount of different constructions used for a referent are associated with the degree of object labelling convergence the participants exhibit after social interaction. More generally, the present study shows that automatically detected shared constructions offer a useful level of analysis to investigate the dynamics of reference negotiation in dialogue.
@inproceedings{ghaleb2024an, title = {Analysing Cross-Speaker Convergence in Face-to-Face Dialogue through the Lens of Automatically Detected Shared Linguistic Constructions}, author = {Ghaleb, Esam and Rasenberg, Marlou and Pouw, Wim and Toni, Ivan and Holler, Judith and {\"O}zy{\"u}rek, Asl{\i} and Fern{\'a}ndez, Raquel}, booktitle = {Proceedings of the Annual Meeting of the Cognitive Science Society}, volume = {45}, number = {45}, year = {2024}, url = {https://escholarship.org/uc/item/43h970fc}, } - WACV24
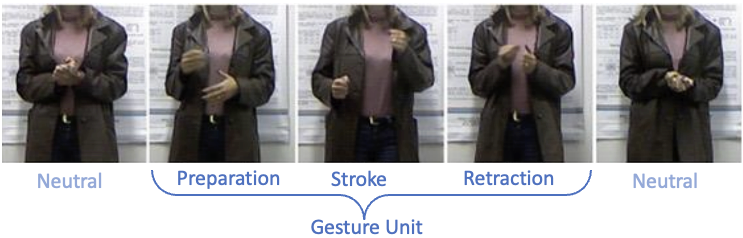 Co-Speech Gesture Detection through Multi-phase Sequence LabelingEsam Ghaleb, Ilya Burenko, Marlou Rasenberg, and 6 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024
Co-Speech Gesture Detection through Multi-phase Sequence LabelingEsam Ghaleb, Ilya Burenko, Marlou Rasenberg, and 6 more authorsIn IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024Gestures are integral components of face-to-face communication. They unfold over time, often following predictable movement phases of preparation, stroke, and retraction. Yet, the prevalent approach to automatic gesture detection treats the problem as binary classification, classifying a segment as either containing a gesture or not, thus failing to capture its inherently sequential and contextual nature. To address this, we introduce a novel framework that reframes the task as a multi-phase sequence labeling problem rather than binary classification. Our model processes sequences of skeletal movements over time windows, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields to perform sequence labeling. We evaluate our proposal on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that our method significantly outperforms strong baseline models in detecting gesture strokes. Furthermore, applying Transformer encoders to learn contextual embeddings from movement sequences substantially improves gesture unit detection. These results highlight our framework’s capacity to capture the fine-grained dynamics of co-speech gesture phases, paving the way for more nuanced and accurate gesture detection and analysis.
@inproceedings{ghaleb2023co, title = {Co-Speech Gesture Detection through Multi-phase Sequence Labeling}, author = {Ghaleb, Esam and Burenko, Ilya and Rasenberg, Marlou and Pouw, Wim and Uhrig, Peter and Holler, Judith and Toni, Ivan and {\"O}zy{\"u}rek, Asl{\i} and Fern{\'a}ndez, Raquel}, booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, year = {2024}, url = {https://arxiv.org/pdf/2308.10680.pdf}, doi = {10.1109/WACV57701.2024.00396}, pages = { 3995-4003}, }
2023
- Joint Modelling of Audio-visual Cues Using Attention Mechanism for Emotion RecognitionEsam Ghaleb, Jan Niehues, and Stylianos AsteriadisMultimedia Tools and Applications, 2023
Emotions play a crucial role in human-human communications with complex socio-psychological nature. In order to enhance emotion communication in human-computer interaction, this paper studies emotion recognition from audio and visual signals in video clips, utilizing facial expressions and vocal utterances. Thereby, the study aims to exploit temporal information of audio-visual cues and detect their informative time segments. Attention mechanisms are used to exploit the importance of each modality over time. We propose a novel framework that consists of bi-modal time windows spanning short video clips labeled with discrete emotions. The framework employs two networks, with each one being dedicated to one modality. As input to a modality-specific network, we consider a time-dependent signal deriving from the embeddings of the video and audio modalities. We employ the encoder part of the Transformer on the visual embeddings and another one on the audio embeddings. The research in this paper introduces detailed studies and meta-analysis findings, linking the outputs of our proposition to research from psychology. Specifically, it presents a framework to understand underlying principles of emotion recognition as functions of three separate setups in terms of modalities: audio only, video only, and the fusion of audio and video. Experimental results on two datasets show that the proposed framework achieves improved accuracy in emotion recognition, compared to state-of-the-art techniques and baseline methods not using attention mechanisms. The proposed method improves the results over baseline methods by at least 5.4%. Our experiments show that attention mechanisms reduce the gap between the entropies of unimodal predictions, which increases the bimodal predictions’ certainty and, therefore, improves the bimodal recognition rates. Furthermore, evaluations with noisy data in different scenarios are presented during the training and testing processes to check the framework’s consistency and the attention mechanism’s behavior. The results demonstrate that attention mechanisms increase the framework’s robustness when exposed to similar conditions during the training and the testing phases. Finally, we present comprehensive evaluations of emotion recognition as a function of time. The study shows that the middle time segments of a video clip are essential in the case of using audio modality. However, in the case of video modality, the importance of time windows is distributed equally.
@article{ghaleb2023joint, title = {Joint Modelling of Audio-visual Cues Using Attention Mechanism for Emotion Recognition}, author = {Ghaleb, Esam and Niehues, Jan and Asteriadis, Stylianos}, journal = {Multimedia Tools and Applications}, volume = {82}, number = {8}, pages = {11239--11264}, year = {2023}, publisher = {Springer}, doi = {10.1007/s11042-022-13557-w}, url = {https://link.springer.com/article/10.1007/s11042-022-13557-w}, keywords = {journal} }
2022
- Dynamic Temperature Scaling in Contrastive Self-supervised Learning for Sensor-based Human Activity RecognitionBulat Khaertdinov, Stylianos Asteriadis, and Esam GhalebIEEE Transactions on Biometrics, Behavior, and Identity Science, 2022
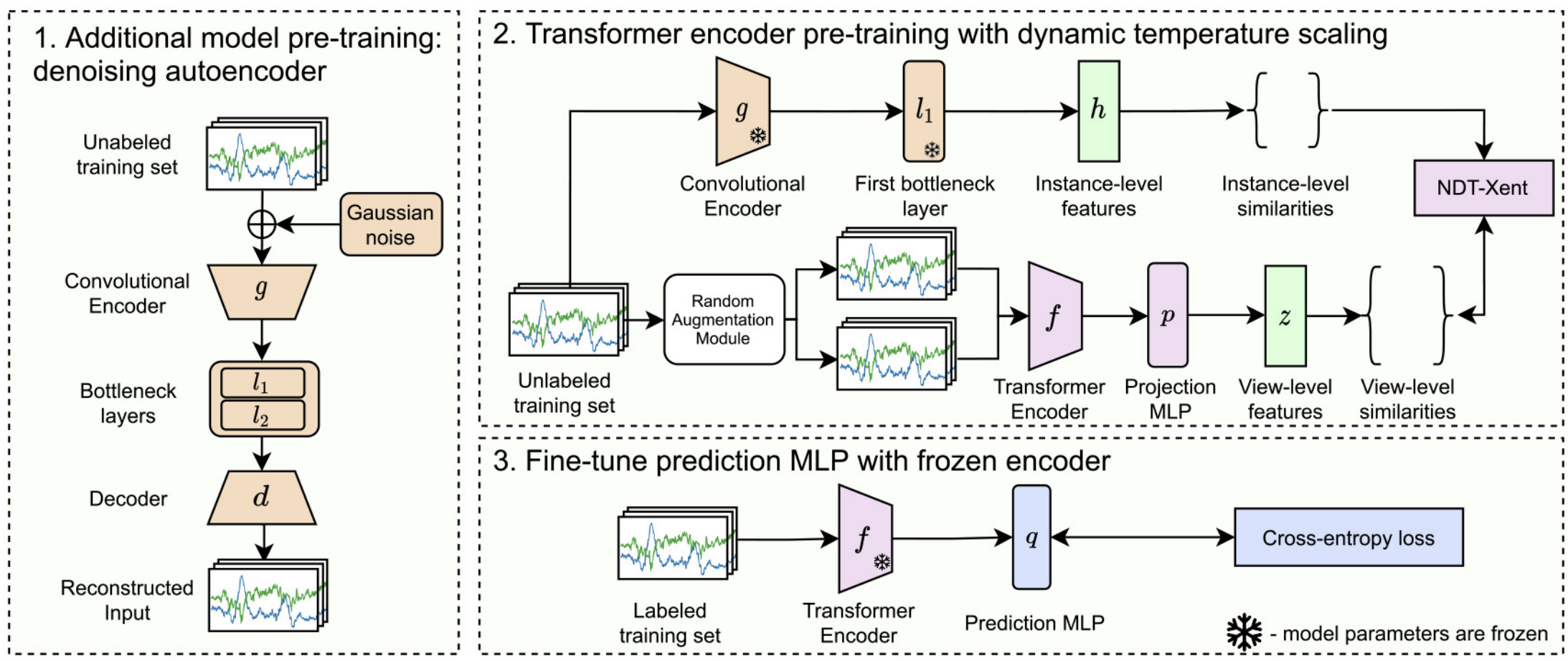
The use of deep neural networks in sensor-based Human Activity Recognition has led to considerably improved recognition rates in comparison to more traditional techniques. Nonetheless, these improvements usually rely on collecting and annotating massive amounts of sensor data, a time-consuming and expensive task. In this paper, inspired by the impressive performance of Contrastive Learning approaches in Self-Supervised Learning settings, we introduce a novel method based on the SimCLR framework and a Transformer-like model. The proposed algorithm addresses the problem of negative pairs in SimCLR by using dynamic temperature scaling within a contrastive loss function. While the original SimCLR framework scales similarities between features of the augmented views by a constant temperature parameter, our method dynamically computes temperature values for scaling. Dynamic temperature is based on instance-level similarity values extracted by an additional model pre-trained on initial instances beforehand. The proposed approach demonstrates state-of-the-art performance on three widely used datasets in sensor-based HAR, namely MobiAct, UCI-HAR and USC-HAD. Moreover, it is more robust than the identical supervised models and models trained with constant temperature in semi-supervised and transfer learning scenarios.
@article{khaertdinov2022dynamic, title = {Dynamic Temperature Scaling in Contrastive Self-supervised Learning for Sensor-based Human Activity Recognition}, author = {Khaertdinov, Bulat and Asteriadis, Stylianos and Ghaleb, Esam}, journal = {IEEE Transactions on Biometrics, Behavior, and Identity Science}, year = {2022}, publisher = {IEEE}, keywords = {journal}, doi = {10.1109/TBIOM.2022.3180591}, url = {https://ieeexplore.ieee.org/document/9790823}, }
2021
- Skeleton-Based Explainable Bodily Expressed Emotion Recognition Through Graph Convolutional NetworksEsam Ghaleb, André Mertens, Stylianos Asteriadis, and 1 more authorIn 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), 2021
Much of the focus on emotion recognition has gone into the face and voice as expressive channels, whereas bodily expressions of emotions are understudied. Moreover, current studies lack the explainability of computational features of body movements related to emotional expressions. Perceptual research on body parts’ movements shows that features related to the arms’ movements are correlated the most with human perception of emotions. In this paper, our research aims at presenting an explainable approach for bodily expressed emotion recognition. It utilizes the body joints of the human skeleton, representing them as a graph, which is used in Graph Convolutional Networks (GCNs). We improve the modelling of the GCNs by using spatial attention mechanisms based on body parts, i.e. arms, legs and torso. Our study presents a state-of-the-art explainable approach supported by experimental results on two challenging datasets. Evaluations show that the proposed methodology offers accurate performance and explainable decisions. The methodology demonstrates which body part contributes the most in its inference, showing the significance of arm movements in emotion recognition.
@inproceedings{ghalebskeleton, title = {Skeleton-Based Explainable Bodily Expressed Emotion Recognition Through Graph Convolutional Networks}, author = {Ghaleb, Esam and Mertens, Andr{\'e} and Asteriadis, Stylianos and Weiss, Gerhard}, booktitle = {2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021)}, year = {2021}, organization = {IEEE}, url = {https://ieeexplore.ieee.org/abstract/document/9667052}, } - UM
 Bimodal emotion recognition through audio-visual cuesEsam GhalebUniversity of Somewhere, 2021
Bimodal emotion recognition through audio-visual cuesEsam GhalebUniversity of Somewhere, 2021Emotions play a crucial role in human-human communication with a complex socio-psychological nature, making emotion recognition a challenging task. In this dissertation, we study emotion recognition from audio and visual cues in video clips, utilizing facial expressions and speech signals, which are among the most prominent emotional expression channels. We propose novel computational methods to capture the complementary information provided by audio-visual cues for enhanced emotion recognition. The research in this dissertation shows how emotion recognition depends on emotion annotation, the perceived modalities, modalities’ robust data representations, and computational modeling. It presents progressive fusion techniques for audio-visual representations that are essential to improve their performance. Furthermore, the methods aim at exploiting the temporal dynamics of audio-visual cues and detect the informative time segments from both modalities. The dissertation presents meta-analysis studies and extensive evaluations for multimodal and temporal emotion recognition.
@phdthesis{ghaleb2021bimodal, author = {Ghaleb, Esam}, title = {Bimodal emotion recognition through audio-visual cues}, school = {University of Somewhere}, year = {2021}, url = {https://cris.maastrichtuniversity.nl/en/publications/bimodal-emotion-recognition-through-audio-visual-cues} } - BNAIC21
 Explainable and Interpretable Features of Emotion in Human Body ExpressionsAndré Mertens, Esam Ghaleb, and Stylianos AsteriadisIn BNAIC/BeneLearn 2021, 2021
Explainable and Interpretable Features of Emotion in Human Body ExpressionsAndré Mertens, Esam Ghaleb, and Stylianos AsteriadisIn BNAIC/BeneLearn 2021, 2021The cooperation between machines and humans could be improved if machines could understand and respond to the emotions of the people around them. Furthermore, the features that machines use to classify emotions should be explainable to reduce the inhibition threshold for automatic emotion recognition. However, the explainability in bodily expressivity of emotions has hardly been explored yet. Therefore, this study aims to visualize and explain the features used by neural networks to classify emotions based on body movements and postures of human characters in videos. For this purpose, a state-of-the-art neural network was selected as classification model. This network was used to classify the videos of two datasets for emotion classification. As a result, the activation of the classification features used by the model were visualized with heatmaps over the course of the videos. Furthermore, a combination of Class Activation Maps and body joint coordinates were used to compute the activation of body parts in order to investigate the existence of prototypical activation patterns in emotions. As a result, similarities were found between the activation patterns of the two datasets. These patterns may provide new insights into the classification features used by neural networks and the emotion expression in body movements and postures.
@inproceedings{maarten2021explainable, title = {Explainable and Interpretable Features of Emotion in Human Body Expressions}, author = {Mertens, André and Ghaleb, Esam and Asteriadis, Stylianos}, booktitle = {BNAIC/BeneLearn 2021}, year = {2021}, } - IJCB21
 Contrastive Self-supervised Learning for Sensor-based Human Activity RecognitionBulat Khaertdinov, Esam Ghaleb, and Stylianos AsteriadisIn 2021 IEEE International Joint Conference on Biometrics (IJCB), 2021
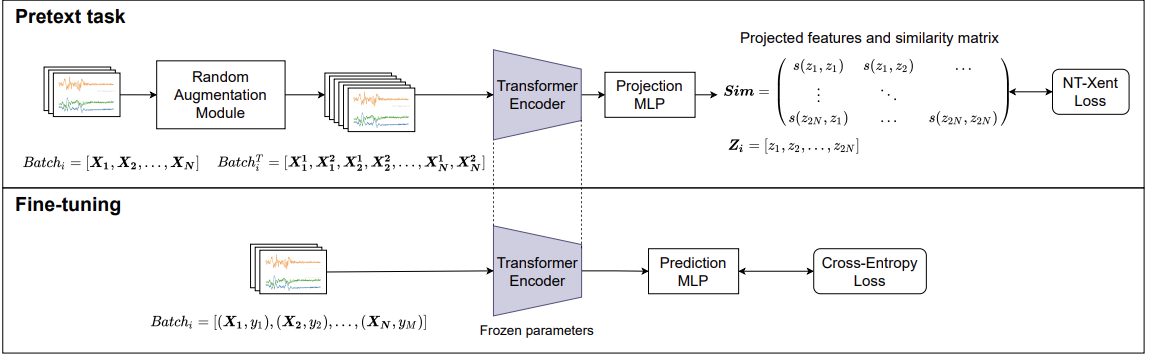
Contrastive Self-supervised Learning for Sensor-based Human Activity RecognitionBulat Khaertdinov, Esam Ghaleb, and Stylianos AsteriadisIn 2021 IEEE International Joint Conference on Biometrics (IJCB), 2021Deep Learning models, applied to a sensor-based Human Activity Recognition task, usually require vast amounts of annotated time-series data to extract robust features. However, annotating signals coming from wearable sensors can be a tedious and, often, not so intuitive process, that requires specialized tools and predefined scenarios, making it an expensive and time-consuming task. This paper combines one of the most recent advances in Self-Supervised Leaning (SSL), namely a SimCLR framework, with a powerful transformer-based encoder to introduce a Contrastive Self-supervised learning approach to Sensor-based Human Activity Recognition (CSSHAR) that learns feature representations from unlabeled sensory data. Extensive experiments conducted on three widely used public datasets have shown that the proposed method outperforms recent SSL models. Moreover, CSSHAR is capable of extracting more robust features than the identical supervised transformer when transferring knowledge from one dataset to another as well as when very limited amounts of annotated data are available.
@inproceedings{khaertdinov2021contrastive, title = {Contrastive Self-supervised Learning for Sensor-based Human Activity Recognition}, author = {Khaertdinov, Bulat and Ghaleb, Esam and Asteriadis, Stylianos}, booktitle = {2021 IEEE International Joint Conference on Biometrics (IJCB)}, pages = {1--8 (\textbf{second runner up award})}, year = {2021}, organization = {IEEE}, } - PerCom
 Deep Triplet Networks with Attention for Sensor-based Human Activity RecognitionBulat Khaertdinov, Esam Ghaleb, and othersIn 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Mar 2021
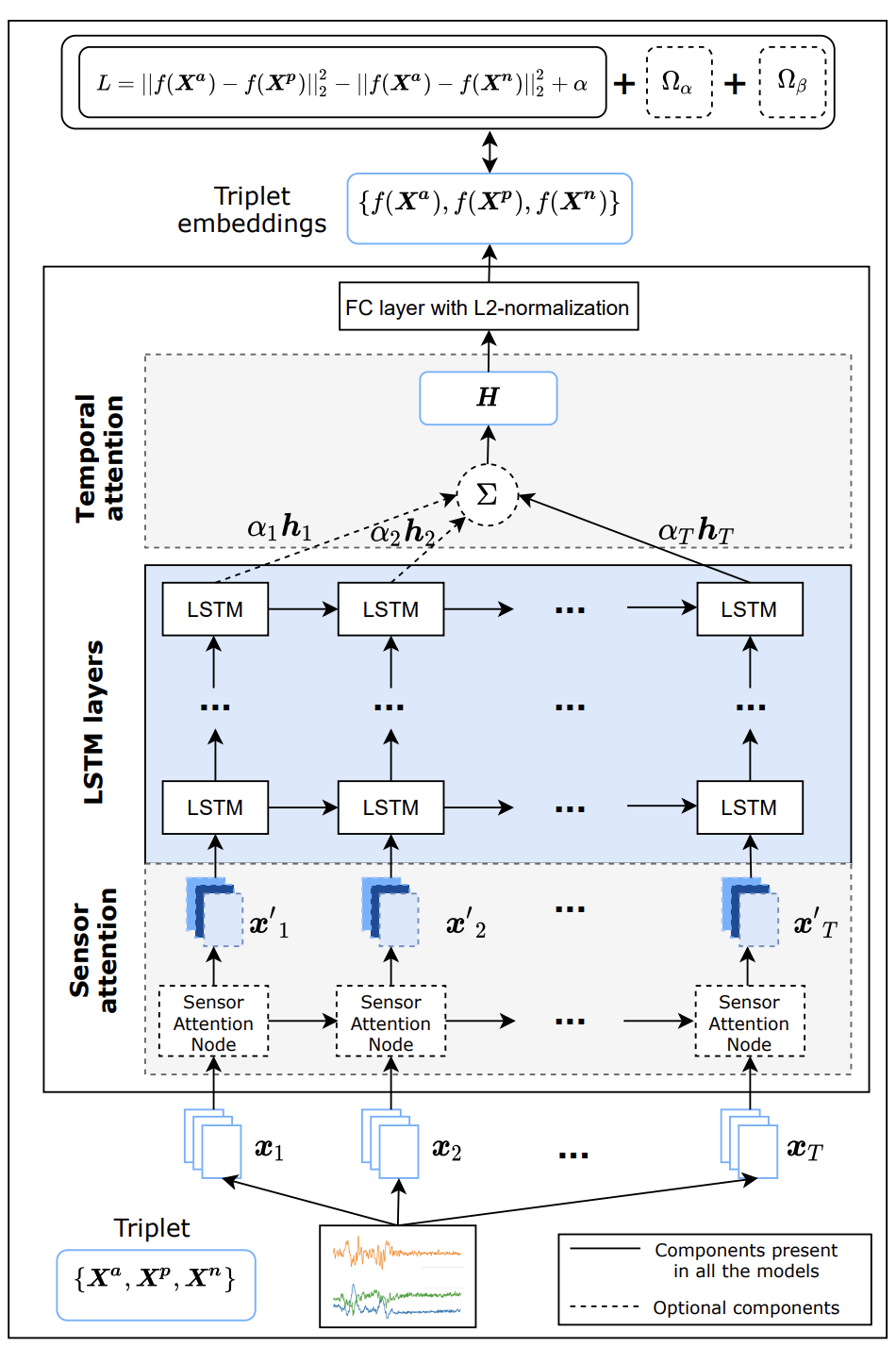
Deep Triplet Networks with Attention for Sensor-based Human Activity RecognitionBulat Khaertdinov, Esam Ghaleb, and othersIn 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Mar 2021One of the most significant challenges in Human Activity Recognition using wearable devices is inter-class similarities and subject heterogeneity. These problems lead to the difficulties in constructing robust feature representations that might negatively affect the quality of recognition. This study, for the first time, applies deep triplet networks with various triplet loss functions and mining methods to the Human Activity Recognition task. Moreover, we introduce a novel method for constructing hard triplets by exploiting similarities between subjects performing the same activities using the concept of Hierarchical Triplet Loss. Our deep triplet models are based on the recent state-of-the-art LSTM networks with two attention mechanisms. The extensive experiments conducted in this paper identify important hyperparameters and settings for training deep metric learning models on widely-used open-source Human Activity Recognition datasets. The comparison of the proposed models against the recent benchmark models shows that deep metric learning approach has the potential to improve the quality of recognition. Specifically, at least one of the implemented triplet networks shows the state-of-the-art results for each dataset used in this study, namely PAMAP2, USC-HAD and MHEALTH. Another positive effect of applying deep triplet networks and especially the proposed sampling algorithm is that feature representations are less affected by inter-class similarities and subject heterogeneity issues.
@inproceedings{khaertdinov2021deep, title = {Deep Triplet Networks with Attention for Sensor-based Human Activity Recognition}, author = {Khaertdinov, Bulat and Ghaleb, Esam and others}, booktitle = {2021 IEEE International Conference on Pervasive Computing and Communications (PerCom)}, pages = {1--10}, year = {2021}, month = mar, organization = {IEEE}, }
2020
- BNAIC20Deep, dimensional and multimodal emotion recognition using attention mechanismsJan Lucas, Esam Ghaleb, and Stylianos AsteriadisIn BNAIC/BeneLearn 2020, 2020
Emotion recognition is an increasingly important sub-field in artificial intelligence (AI). Advances in this field could drastically change the way people interact with computers and allow for automation of tasks that currently require a lot of manual work. For example, registering the emotion a subject expresses for a potential advert. Previous work has shown that using multiple modalities, although challenging, is very beneficial. Affective cues in audio and video may not occur simultaneously, and the modalities do not always contribute equally to emotion. This work seeks to apply attention mechanisms to aid in the fusion of audio and video, for the purpose of emotion recognition using state-of-the-art techniques from artificial intelligence and, more specifically, deep neural networks. To achieve this, two forms of attention are used. Embedding attention applies attention on the input of a modalityspecific model, allowing recurrent networks to consider multiple input time steps. Bimodal attention fusion applies attention to fuse the output of modality-specific networks. Combining both these attention mechanisms yielded CCCs of 0.62 and 0.72 for arousal and valence respectively on the RECOLA dataset used in AVEC 2016. These results are competitive with the state-of-the-art, underlying the potential of attention mechanisms in multimodal fusion for behavioral signals.
@inproceedings{lucas2020deep, title = {Deep, dimensional and multimodal emotion recognition using attention mechanisms}, author = {Lucas, Jan and Ghaleb, Esam and Asteriadis, Stylianos}, booktitle = {BNAIC/BeneLearn 2020}, pages = {130}, year = {2020}, } - ICIP20
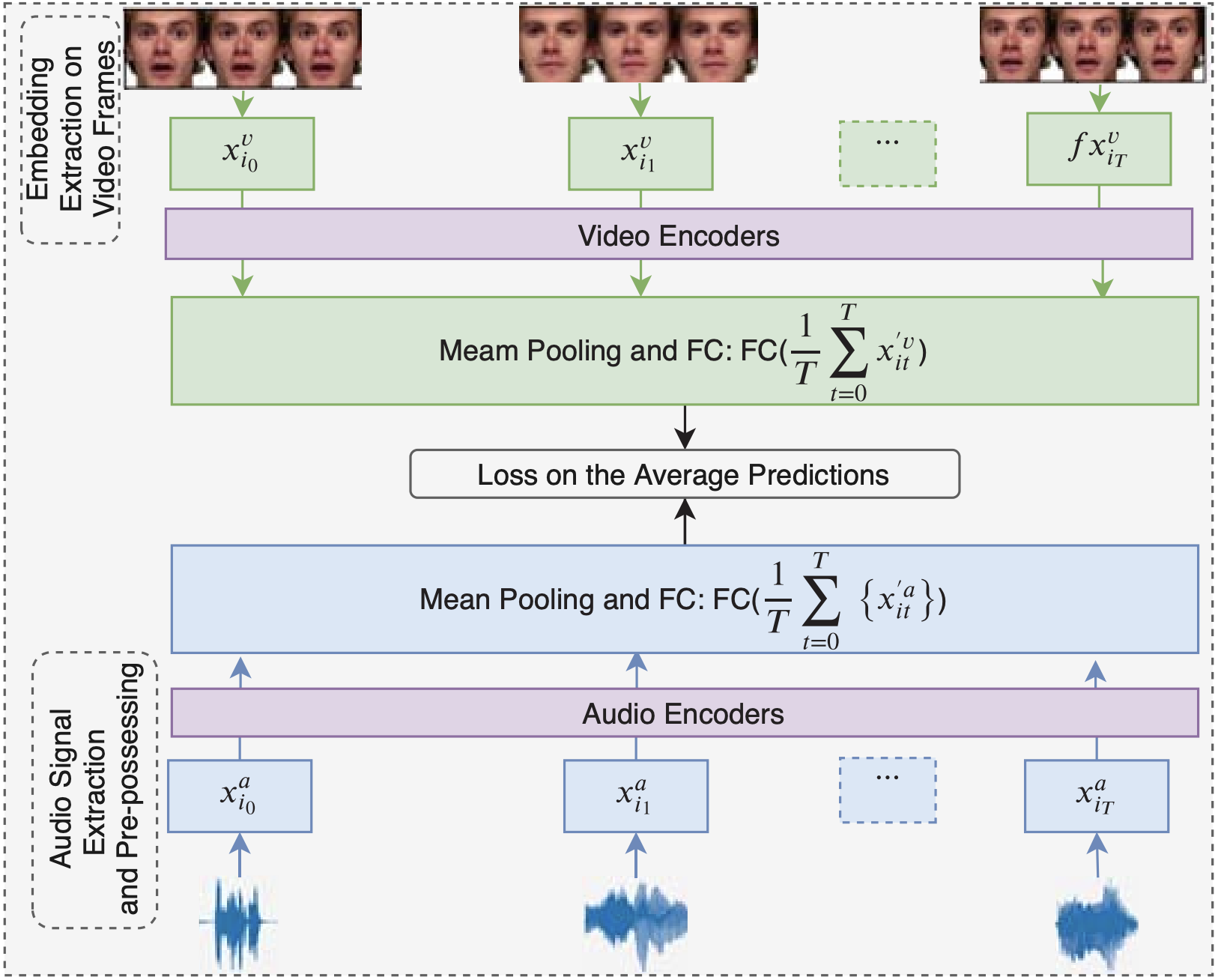 Multimodal Attention-Mechanism For Temporal Emotion RecognitionEsam Ghaleb, Jan Niehues, and Stylianos AsteriadisIn 2020 IEEE International Conference on Image Processing (ICIP), 2020
Multimodal Attention-Mechanism For Temporal Emotion RecognitionEsam Ghaleb, Jan Niehues, and Stylianos AsteriadisIn 2020 IEEE International Conference on Image Processing (ICIP), 2020Exploiting the multimodal and temporal interaction between audio-visual channels is essential for automatic audio-video emotion recognition (AVER). Modalities’ strength in emotions and time-window of a video-clip could be further utilized through a weighting scheme such as attention mechanism to capture their complementary information. The attention mechanism is a powerful approach for sequence modeling, which can be employed to fuse audio-video cues overtime. We propose a novel framework which consists of biaudio-visual time-windows that span short video-clips labeled with discrete emotions. Attention is used to weigh these time windows for multimodal learning and fusion. Experimental results on two datasets show that the proposed methodology can achieve an enhanced multimodal emotion recognition.
@inproceedings{ghaleb2020multimodal, title = {Multimodal Attention-Mechanism For Temporal Emotion Recognition}, author = {Ghaleb, Esam and Niehues, Jan and Asteriadis, Stylianos}, booktitle = {2020 IEEE International Conference on Image Processing (ICIP)}, pages = {251--255}, year = {2020}, organization = {IEEE}, } - FG20
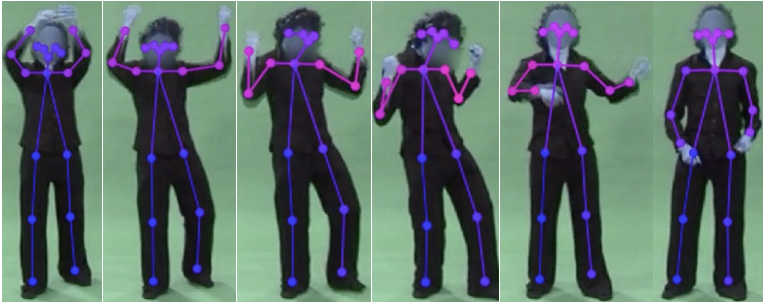
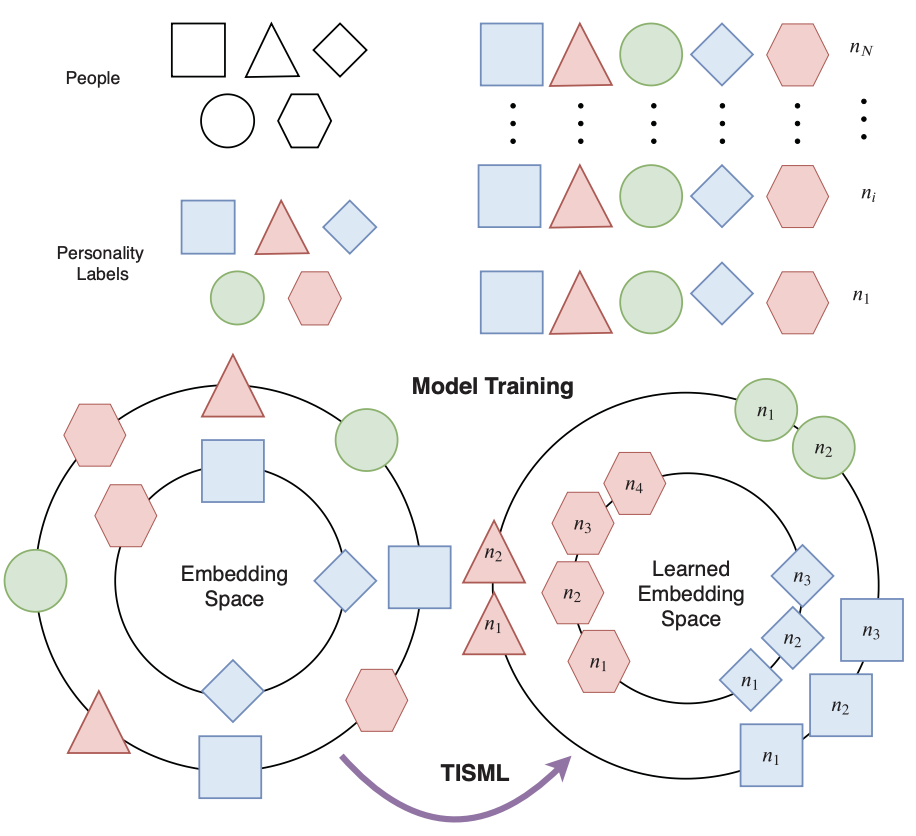 Temporal triplet mining for personality recognitionDario Dotti, Esam Ghaleb, and Stylianos AsteriadisIn 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), 2020
Temporal triplet mining for personality recognitionDario Dotti, Esam Ghaleb, and Stylianos AsteriadisIn 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), 2020One of the primary goals of personality computing is to enhance the automatic understanding of human behavior, making use of various sensing technologies. Recent studies have started to correlate personality patterns described by psychologists with data findings, however, given the subtle delineations of human behaviors, results are specific to predefined contexts. In this paper, we propose a framework for automatic personality recognition that is able to embed different behavioral dynamics evoked by diverse real world scenarios. Specifically, motion features are designed to encode local motion dynamics from the human body, and interpersonal distance (proxemics) features are designed to encode global dynamics in the scene. By using a Convolutional Neural Network (CNN) architecture which utilizes a triplet loss deep metric learning, we learn temporal, as well as discriminative spatio-temporal streams of embeddings to represent patterns of personality behaviors. We experimentally show that the proposed Temporal Triplet Mining strategy leverages the similarity between temporally related samples and, therefore, helps to encode higher semantic movements or sub-movements which are easier to map onto personality labels. Our experiments show that the generated embeddings improve the state-of-the-art results of personality recognition on two public datasets, recorded in different scenarios.
@inproceedings{dotti2020temporal, title = {Temporal triplet mining for personality recognition}, author = {Dotti, Dario and Ghaleb, Esam and Asteriadis, Stylianos}, booktitle = {2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020)}, pages = {379--386}, year = {2020}, organization = {IEEE}, }
2019
- ACII19
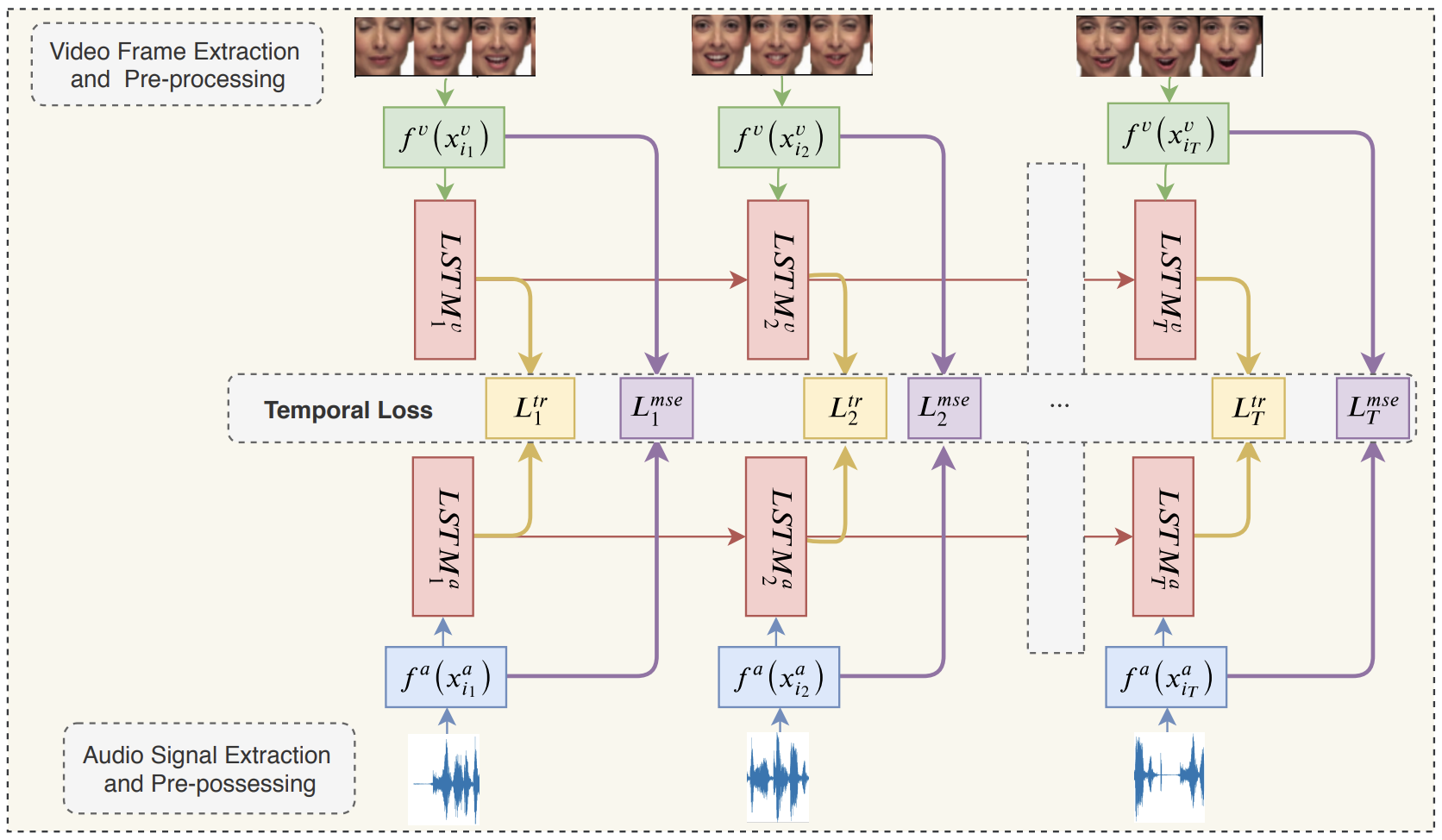 Multimodal and temporal perception of audio-visual cues for emotion recognitionEsam Ghaleb, Mirela Popa, and Stylianos AsteriadisIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), 2019
Multimodal and temporal perception of audio-visual cues for emotion recognitionEsam Ghaleb, Mirela Popa, and Stylianos AsteriadisIn 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), 2019In Audio-Video Emotion Recognition (AVER), the idea is to have a human-level understanding of emotions from video clips. There is a need to bring these two modalities into a unified framework, to effectively learn multimodal fusion for AVER. In addition, literature studies lack in-depth analysis and utilization of how emotions vary as a function of time. Psychological and neurological studies show that negative and positive emotions are not recognized at the same speed. In this paper, we propose a novel multimodal temporal deep network framework that embeds video clips using their audio-visual content, onto a metric space, where their gap is reduced and their complementary and supplementary information is explored. We address two research questions, (1) how audio-visual cues contribute to emotion recognition and (2) how temporal information impacts the recognition rate and speed of emotions. The proposed method is evaluated on two datasets, CREMA-D and RAVDESS. The study findings are promising, achieving the state-of-the-art performance on both datasets, and showing a significant impact of multimodal and temporal emotion perception.
@inproceedings{ghaleb2019multimodal, title = {Multimodal and temporal perception of audio-visual cues for emotion recognition}, author = {Ghaleb, Esam and Popa, Mirela and Asteriadis, Stylianos}, booktitle = {2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII)}, pages = {552--558}, year = {2019}, organization = {IEEE}, } - IEEE Multimedia
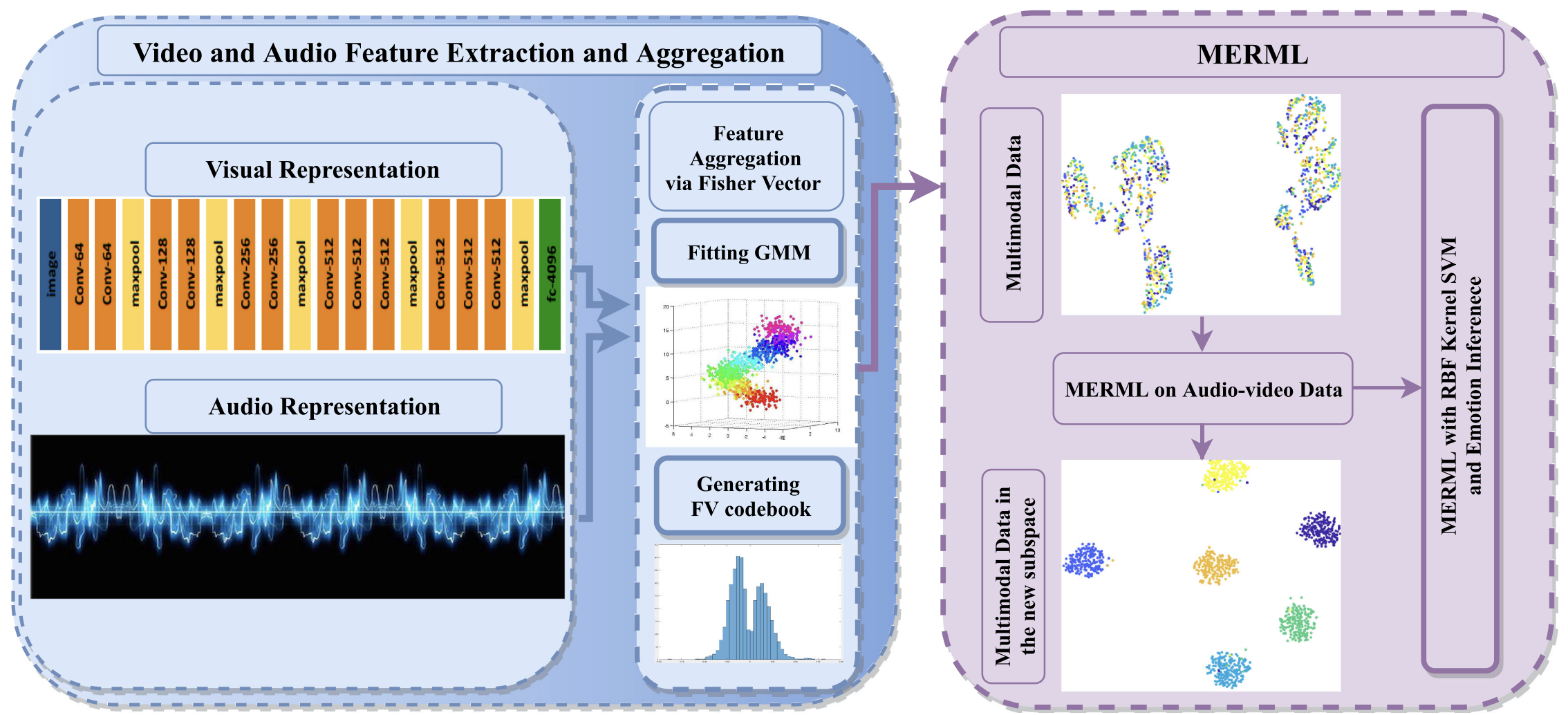 Metric learning-based multimodal audio-visual emotion recognitionEsam Ghaleb, Mirela Popa, and Stylianos AsteriadisIeee Multimedia, 2019
Metric learning-based multimodal audio-visual emotion recognitionEsam Ghaleb, Mirela Popa, and Stylianos AsteriadisIeee Multimedia, 2019People express their emotions through multiple channels, such as visual and audio ones. Consequently, automatic emotion recognition can be significantly benefited by multimodal learning. Even-though each modality exhibits unique characteristics; multimodal learning takes advantage of the complementary information of diverse modalities when measuring the same instance, resulting in enhanced understanding of emotions. Yet, their dependencies and relations are not fully exploited in audio–video emotion recognition. Furthermore, learning an effective metric through multimodality is a crucial goal for many applications in machine learning. Therefore, in this article, we propose multimodal emotion recognition metric learning (MERML), learned jointly to obtain a discriminative score and a robust representation in a latent-space for both modalities. The learned metric is efficiently used through the radial basis function (RBF) based support vector machine (SVM) kernel. The evaluation of our framework shows a significant performance, improving the state-of-the-art results on the eNTERFACE and CREMA-D datasets.
@article{ghaleb2019metric, title = {Metric learning-based multimodal audio-visual emotion recognition}, author = {Ghaleb, Esam and Popa, Mirela and Asteriadis, Stylianos}, journal = {Ieee Multimedia}, volume = {27}, number = {1}, pages = {37--48}, year = {2019}, publisher = {IEEE}, keywords = {journal}, } - VR
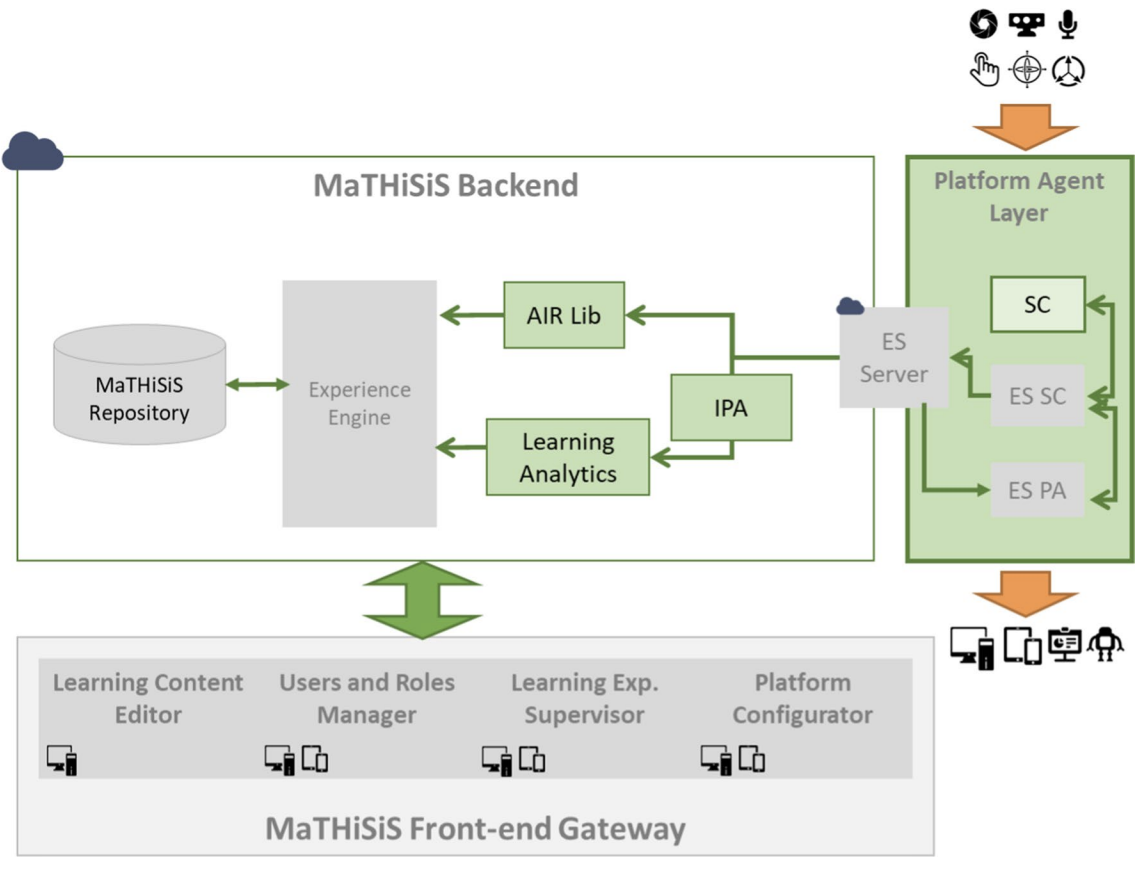 Exploiting sensing devices availability in AR/VR deployments to foster engagementNicholas Vretos, Petros Daras, Stylianos Asteriadis, and 7 more authorsVirtual Reality, 2019
Exploiting sensing devices availability in AR/VR deployments to foster engagementNicholas Vretos, Petros Daras, Stylianos Asteriadis, and 7 more authorsVirtual Reality, 2019Currently, in all augmented reality (AR) or virtual reality (VR) educational experiences, the evolution of the experience (game, exercise or other) and the assessment of the user’s performance are based on her/his (re)actions which are continuously traced/sensed. In this paper, we propose the exploitation of the sensors available in the AR/VR systems to enhance the current AR/VR experiences, taking into account the users’ affect state that changes in real time. Adapting the difficulty level of the experience to the users’ affect state fosters their engagement which is a crucial issue in educational environments and prevents boredom and anxiety. The users’ cues are processed enabling dynamic user profiling. The detection of the affect state based on different sensing inputs, since diverse sensing devices exist in different AR/VR systems, is investigated, and techniques that have been undergone validation using state-of-the-art sensors are presented.
@article{vretos2019exploiting, title = {Exploiting sensing devices availability in AR/VR deployments to foster engagement}, author = {Vretos, Nicholas and Daras, Petros and Asteriadis, Stylianos and Hortal, Enrique and Ghaleb, Esam and Spyrou, Evaggelos and Leligou, Helen C and Karkazis, Panagiotis and Trakadas, Panagiotis and Assimakopoulos, Kostantinos}, journal = {Virtual Reality}, volume = {23}, number = {4}, pages = {399--410}, year = {2019}, publisher = {Springer}, keywords = {journal}, }
2018
- ICMLA18
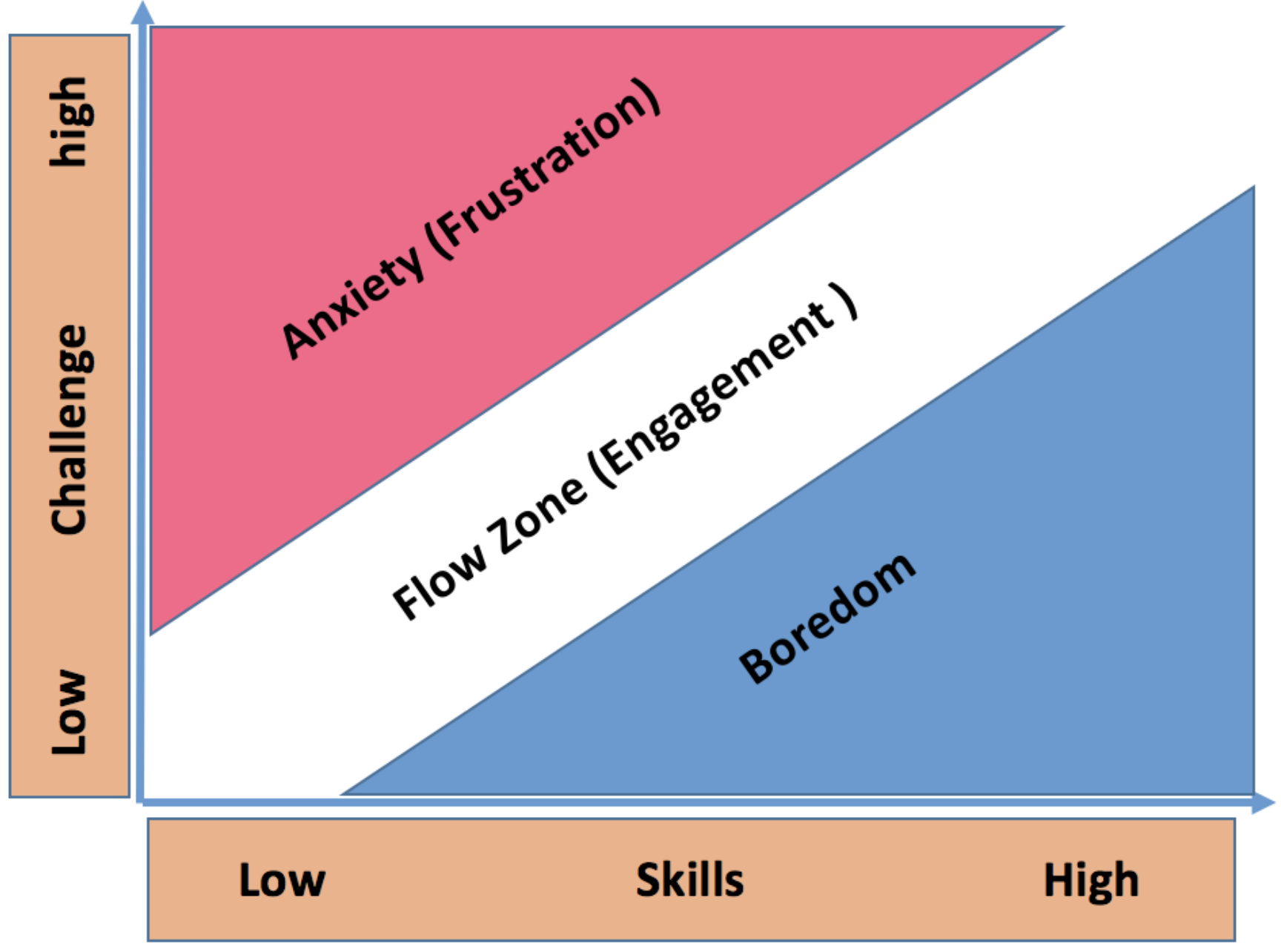 Towards Affect Recognition through Interactions with Learning MaterialsEsam Ghaleb, Mirela Popa, Enrique Hortal, and 2 more authorsIn Machine Learning and Applications (ICMLA), 2018 17th International Conference on, 2018
Towards Affect Recognition through Interactions with Learning MaterialsEsam Ghaleb, Mirela Popa, Enrique Hortal, and 2 more authorsIn Machine Learning and Applications (ICMLA), 2018 17th International Conference on, 2018Affective state recognition has recently attracted a notable amount of attention in the research community, as it can be directly linked to a student’s performance during learning. Consequently, being able to retrieve the affect of a student can lead to more personalized education, targeting higher degrees of engagement and, thus, optimizing the learning experience and its outcomes. In this paper, we apply Machine Learning (ML) and present a novel approach for affect recognition in Technology-Enhanced Learning (TEL) by understanding learners’ experience through tracking their interactions with a serious game as a learning platform. We utilize a variety of interaction parameters to examine their potential to be used as an indicator of the learner’s affective state. Driven by the Theory of Flow model, we investigate the correspondence between the prediction of users’ self-reported affective states and the interaction features. Cross-subject evaluation using Support Vector Machines (SVMs) on a dataset of 32 participants interacting with the platform demonstrated that the proposed framework could achieve a significant precision in affect recognition. The subject-based evaluation highlighted the benefits of an adaptive personalized learning experience, contributing to achieving optimized levels of engagement.
@inproceedings{ghaleb2018towards, title = {Towards Affect Recognition through Interactions with Learning Materials}, author = {Ghaleb, Esam and Popa, Mirela and Hortal, Enrique and Asteriadis, Stylianos and Weiss, Gerhard}, booktitle = {Machine Learning and Applications (ICMLA), 2018 17th International Conference on}, pages = {76--79}, year = {2018}, organization = {IEEE}, } - IEEE IS
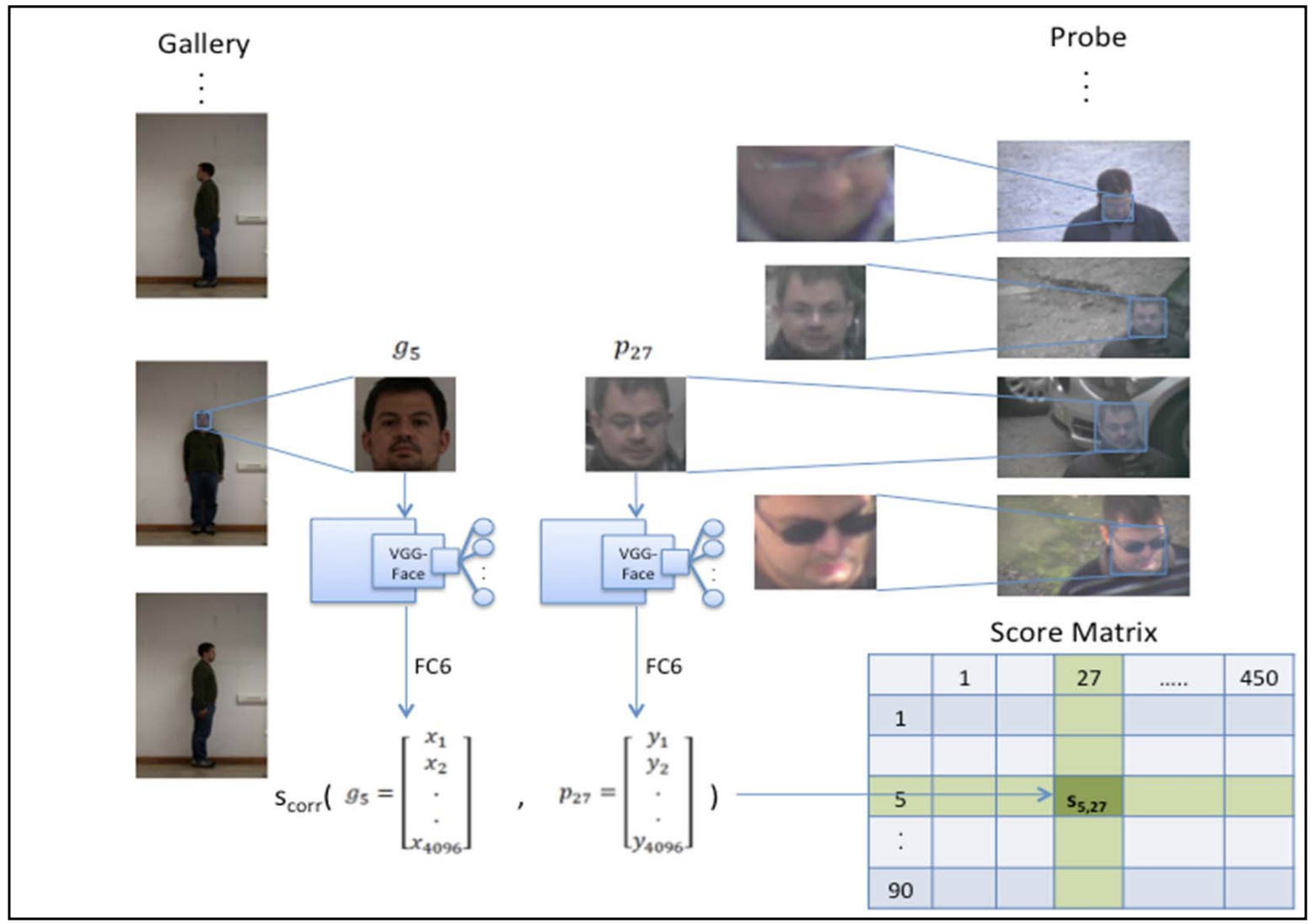 DEEP REPRESENTATION AND SCORE NORMALIZATION FOR FACE RECOGNITION UNDER MISMATCHED CONDITIONSEsam Ghaleb, Gokhan Ozbulak, Hua Gao, and 1 more author2018
DEEP REPRESENTATION AND SCORE NORMALIZATION FOR FACE RECOGNITION UNDER MISMATCHED CONDITIONSEsam Ghaleb, Gokhan Ozbulak, Hua Gao, and 1 more author2018Face recognition under unconstrained conditions is a challenging computer vision task. Identification under mismatched conditions, for example, due to difference of view angles, illumination conditions, and image quality between galley and probe images, as in the International Challenge on Biometric Recognition-in-the-Wild (ICB-RW) 2016, poses even further challenges. In our work, to address this problem, we have employed facial image preprocessing, deep representation, and score normalization methods to develop a successful face recognition system. In the preprocessing step, we have aligned the gallery and probe face images with respect to automatically detected eye centers. We only used frontal faces as a gallery. For face representation, we have employed a state-of-the-art deep convolutional neural network model, namely the VGGFace model. For classification, we have applied a nearest neighbor classifier with correlation distance as the distance metric. As the final step, we normalized the resulting similarity score matrix, which includes the scores of all face images in the probe set against all face images in the gallery set, with z-score normalization. The proposed system has achieved 69.8 percent Rank-1 and 85.3 percent Rank-5 accuracy on the test set, which were the highest accuracies obtained in the challenge.
@article{ghaleb2018deep, title = {DEEP REPRESENTATION AND SCORE NORMALIZATION FOR FACE RECOGNITION UNDER MISMATCHED CONDITIONS}, author = {Ghaleb, Esam and Ozbulak, Gokhan and Gao, Hua and Ekenel, Hazim Kemal}, issuetitle = {Trends and Controversies, IEEE Intelligent Systems}, volume = {33}, issue = {3}, year = {2018}, pages = {43-46}, publisher = {IEEE}, keywords = {journal}, }
2017
- SMAP17
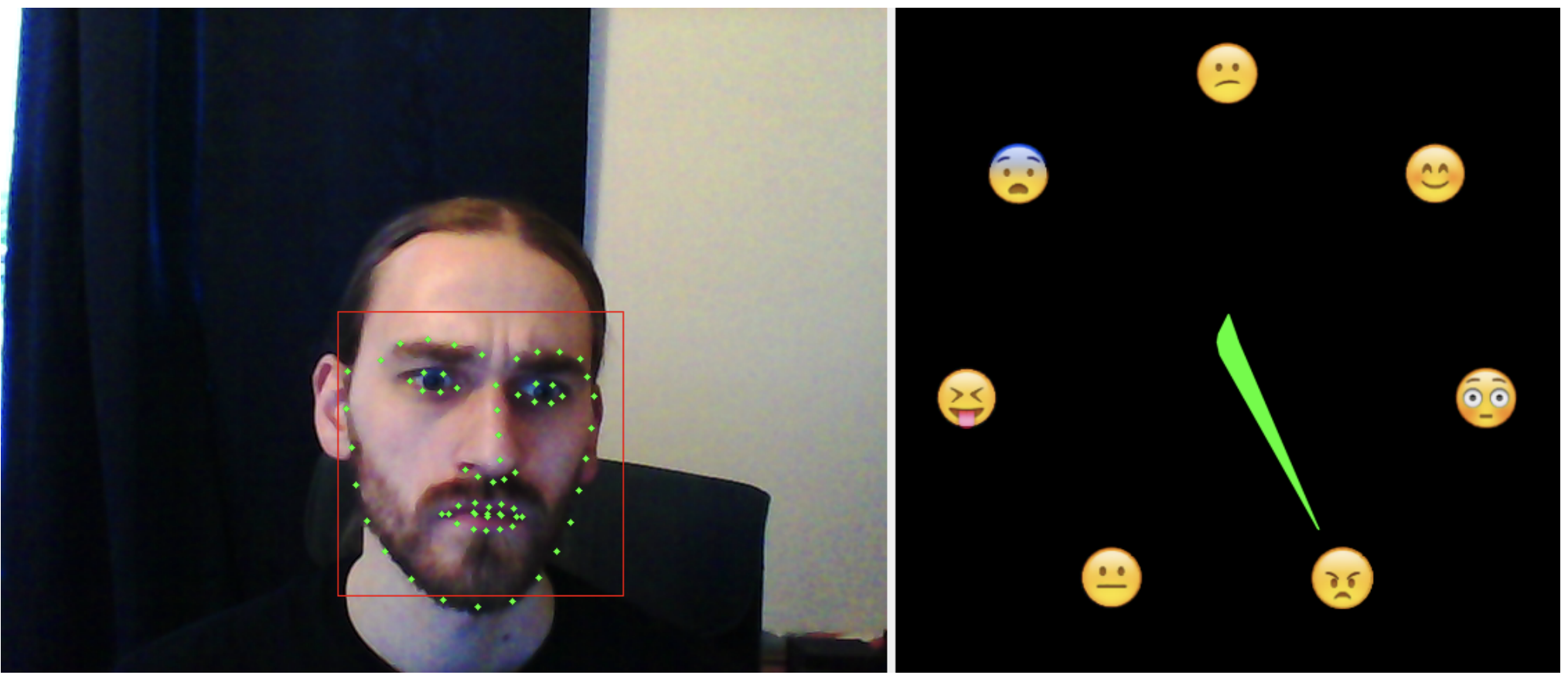 High-performance and lightweight real-time deep face emotion recognitionJustus Schwan, Esam Ghaleb, Enrique Hortal, and 1 more authorIn Semantic and Social Media Adaptation and Personalization (SMAP), 2017 12th International Workshop on, 2017
High-performance and lightweight real-time deep face emotion recognitionJustus Schwan, Esam Ghaleb, Enrique Hortal, and 1 more authorIn Semantic and Social Media Adaptation and Personalization (SMAP), 2017 12th International Workshop on, 2017Deep learning is used for all kinds of tasks which require human-like performance, such as voice and image recognition in smartphones, smart home technology, and self-driving cars. While great advances have been made in the field, results are often not satisfactory when compared to human performance. In the field of facial emotion recognition, especially in the wild, Convolutional Neural Networks (CNN) are employed because of their excellent generalization properties. However, while CNNs can learn a representation for certain object classes, an amount of (annotated) training data roughly proportional to the class’s complexity is needed and seldom available. This work describes an advanced pre-processing algorithm for facial images and a transfer learning mechanism, two potential candidates for relaxing this requirement. Using these algorithms, a lightweight face emotion recognition application for Human-Computer Interaction with TurtleBot units was developed.
@inproceedings{schwan2017high, title = {High-performance and lightweight real-time deep face emotion recognition}, author = {Schwan, Justus and Ghaleb, Esam and Hortal, Enrique and Asteriadis, Stylianos}, booktitle = {Semantic and Social Media Adaptation and Personalization (SMAP), 2017 12th International Workshop on}, pages = {76--79}, year = {2017}, organization = {IEEE}, } - IntelliSys17
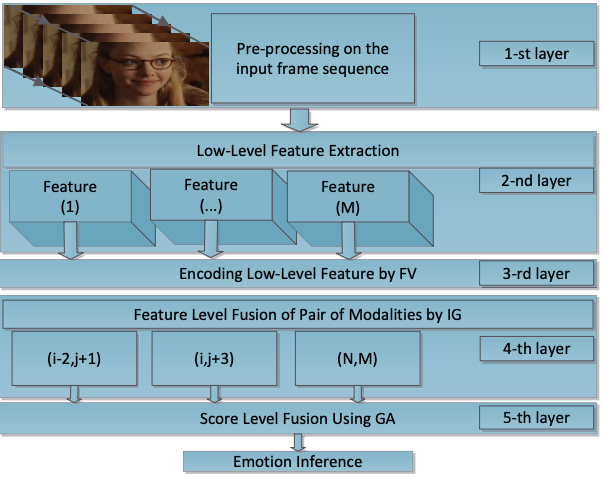 Multimodal fusion based on information gain for emotion recognition in the wildEsam Ghaleb, Mirela Popa, Enrique Hortal, and 1 more authorIn Intelligent Systems Conference (IntelliSys), 2017, 2017
Multimodal fusion based on information gain for emotion recognition in the wildEsam Ghaleb, Mirela Popa, Enrique Hortal, and 1 more authorIn Intelligent Systems Conference (IntelliSys), 2017, 2017@inproceedings{ghaleb2017multimodal, title = {Multimodal fusion based on information gain for emotion recognition in the wild}, author = {Ghaleb, Esam and Popa, Mirela and Hortal, Enrique and Asteriadis, Stylianos}, booktitle = {Intelligent Systems Conference (IntelliSys), 2017}, pages = {814--823}, year = {2017}, organization = {IEEE}, }
2015
- ICMR15
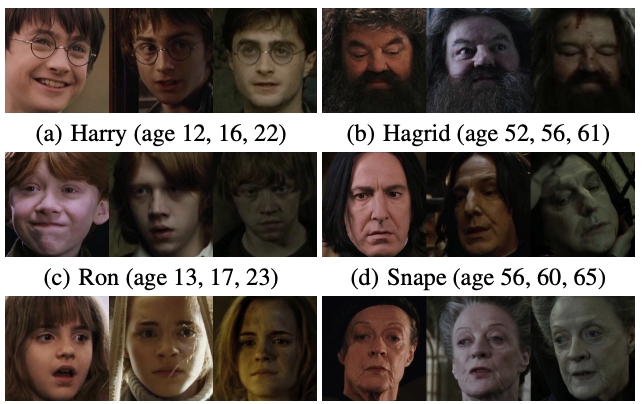 Accio: A data set for face track retrieval in movies across ageEsam Ghaleb, Makarand Tapaswi, Ziad Al-Halah, and 2 more authorsIn Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, 2015
Accio: A data set for face track retrieval in movies across ageEsam Ghaleb, Makarand Tapaswi, Ziad Al-Halah, and 2 more authorsIn Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, 2015In this paper we present a novel approach towards multi-modal emotion recognition on a challenging dataset AFEW’16, composed of video clips labeled with the six basic emotions plus the neutral state. After a preprocessing stage, we employ different feature extraction techniques (CNN, DSIFT on face and facial ROI, geometric and audio based) and encoded frame-based features using Fisher vector representations. Next, we leverage the properties of each modality using different fusion schemes. Apart from the early-level fusion and the decision level fusion approaches, we propose a hierarchical decision level method based on information gain principles and we optimize its parameters using genetic algorithms. The experimental results prove the suitability of our method, as we obtain 53.06% validation accuracy, surpassing by 14% the baseline of 38.81% on a challenging dataset, suitable for emotion recognition in the wild.
@inproceedings{ghaleb2015accio, title = {Accio: A data set for face track retrieval in movies across age}, author = {Ghaleb, Esam and Tapaswi, Makarand and Al-Halah, Ziad and Ekenel, Hazim Kemal and Stiefelhagen, Rainer}, booktitle = {Proceedings of the 5th ACM on International Conference on Multimedia Retrieval}, pages = {455--458}, year = {2015}, organization = {ACM}, }
2014
- IFIP14
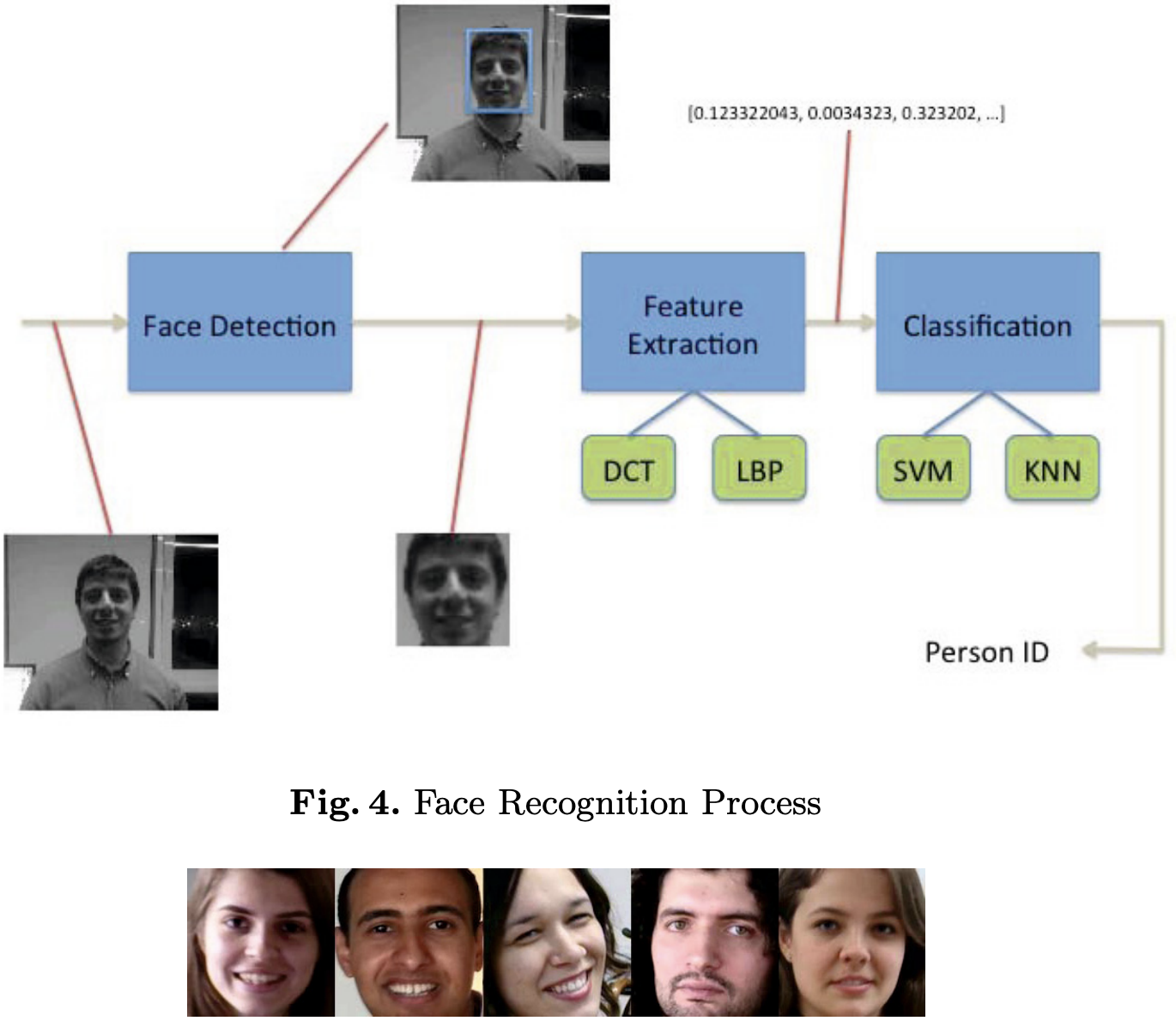 A Face Recognition Based Multiplayer Mobile Game ApplicationUgur Demir, Esam Ghaleb, and Hazım Kemal EkenelIn IFIP International Conference on Artificial Intelligence Applications and Innovations, 2014
A Face Recognition Based Multiplayer Mobile Game ApplicationUgur Demir, Esam Ghaleb, and Hazım Kemal EkenelIn IFIP International Conference on Artificial Intelligence Applications and Innovations, 2014In this paper, we present a multiplayer mobile game application that aims at enabling individuals play paintball or laser tag style games using their smartphones. In the application, face detection and recognition technologies are utilised to detect and identify the individuals, respectively. In the game, first, one of the players starts the game and invites the others to join. Once everyone joins the game, they receive a notification for the training stage, at which they need to record another player’s face for a short time. After the completion of the training stage, the players can start shooting each other, that is, direct the smartphone to another user and when the face is visible, press the shoot button on the screen. Both the shooter and the one who is shot are notified by the system after a successful hit. To realise this game in real-time, fast and robust face detection and face recognition algorithms have been employed. The face recognition performance of the system is benchmarked on the face data collected from the game, when it is played with up to ten players. It is found that the system is able to identify the players with a success rate of around or over 90% depending on the number of players in the game.
@inproceedings{demir2014face, title = {A Face Recognition Based Multiplayer Mobile Game Application}, author = {Demir, Ugur and Ghaleb, Esam and Ekenel, Haz{\i}m Kemal}, booktitle = {IFIP International Conference on Artificial Intelligence Applications and Innovations}, pages = {214--223}, year = {2014}, organization = {Springer}, } - SIU14
 An energy efficient routing technique and implementation in WSNsAbdullah Aydeger, Esam Ghaleb, and Sema OktugIn Signal Processing and Communications Applications Conference (SIU), 2014 22nd, 2014
An energy efficient routing technique and implementation in WSNsAbdullah Aydeger, Esam Ghaleb, and Sema OktugIn Signal Processing and Communications Applications Conference (SIU), 2014 22nd, 2014In this work, an energy efficient routing technique for WSNs is introduced. Here the routes between the source nodes and the base station are formed considering the energy levels of the intermediate nodes. These routes are refreshed dynamically to recover topology changes and to keep the energy level of the nodes close to each other. The technique introduced together with data aggregation are implemented on the WSN testbed at the department of computer enngineering, ITU. The results obtained have shown that the routing technique introduced and data aggregation contribute to the lifetime of WSNs.
@inproceedings{aydeger2014energy, title = {An energy efficient routing technique and implementation in WSNs}, author = {Aydeger, Abdullah and Ghaleb, Esam and Oktug, Sema}, booktitle = {Signal Processing and Communications Applications Conference (SIU), 2014 22nd}, pages = {1359--1362}, year = {2014}, organization = {IEEE}, }