My PhD thesis on audio & video based emotion recognition
My Ph.D. dissertation addressed the research problem of automatic multimodal emotion recognition using audio and visual cues. It approached this problem through several methods and proposed techniques to exploit audio and video channels’ complementary and supplementary information. The studies conducted in my Ph.D. work targeted several aspects of multimodal emotion recognition, such as investigating various representations of audio and visual cues, proposing fusion algorithms, utilizing the temporal information in a video clip to integrate both modalities and studying the patterns and behavior of audio-video signals for emotion recognition as a function of time. You can access my Ph.D. dissertation from the following link:
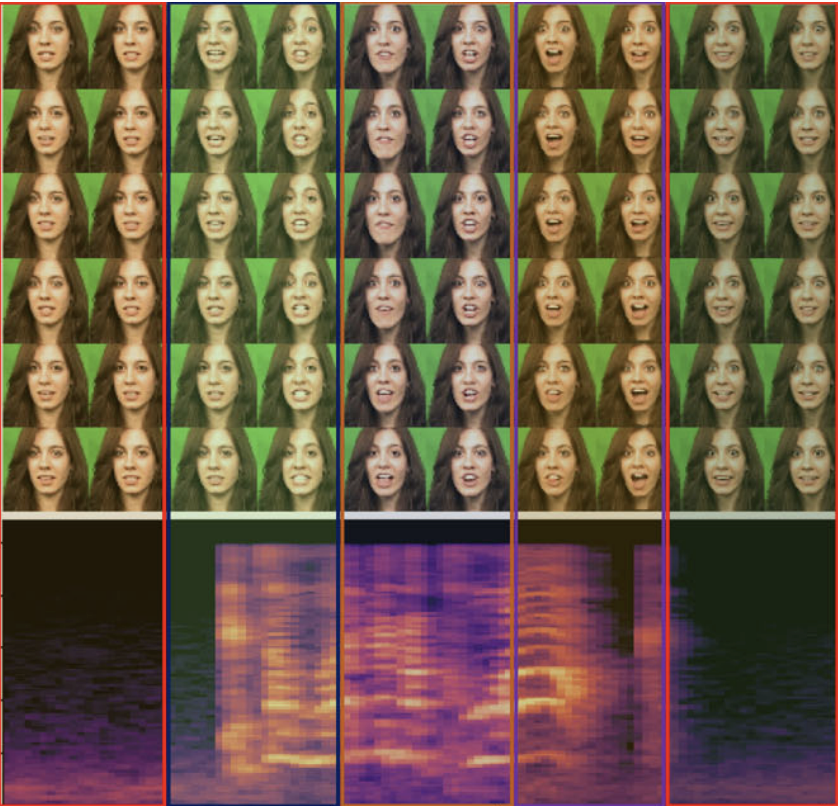
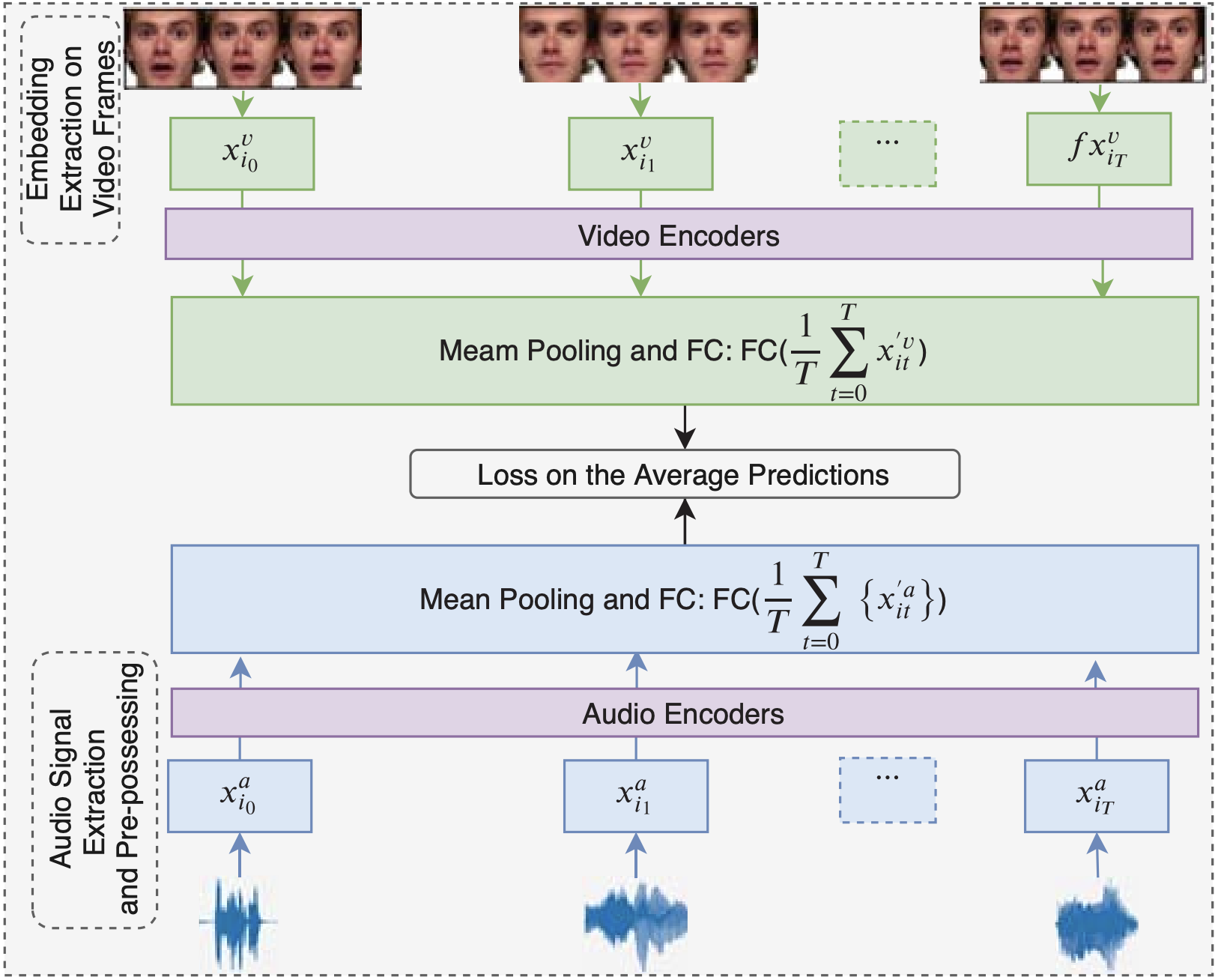
Emotions play a crucial role in human-human communications with complex socio-psychological nature. In order to enhance emotion communication in human-computer interaction, this paper studies emotion recognition from audio and visual signals in video clips, utilizing facial expressions and vocal utterances. Thereby, the study aims to exploit temporal information of audio-visual cues and detect their informative time segments. Attention mechanisms are used to exploit the importance of each modality over time. We propose a novel framework that consists of bi-modal time windows spanning short video clips labeled with discrete emotions. The framework employs two networks, with each one being dedicated to one modality. As input to a modality-specific network, we consider a time-dependent signal deriving from the embeddings of the video and audio modalities. We employ the encoder part of the Transformer on the visual embeddings and another one on the audio embeddings. The research in this paper introduces detailed studies and meta-analysis findings, linking the outputs of our proposition to research from psychology. Specifically, it presents a framework to understand underlying principles of emotion recognition as functions of three separate setups in terms of modalities: audio only, video only, and the fusion of audio and video. Experimental results on two datasets show that the proposed framework achieves improved accuracy in emotion recognition, compared to state-of-the-art techniques and baseline methods not using attention mechanisms. The proposed method improves the results over baseline methods by at least 5.4%. Our experiments show that attention mechanisms reduce the gap between the entropies of unimodal predictions, which increases the bimodal predictions’ certainty and, therefore, improves the bimodal recognition rates. Furthermore, evaluations with noisy data in different scenarios are presented during the training and testing processes to check the framework’s consistency and the attention mechanism’s behavior. The results demonstrate that attention mechanisms increase the framework’s robustness when exposed to similar conditions during the training and the testing phases. Finally, we present comprehensive evaluations of emotion recognition as a function of time. The study shows that the middle time segments of a video clip are essential in the case of using audio modality. However, in the case of video modality, the importance of time windows is distributed equally.
@article{ghaleb2023joint,title={Joint Modelling of Audio-visual Cues Using Attention Mechanism for Emotion Recognition},author={Ghaleb, Esam and Niehues, Jan and Asteriadis, Stylianos},journal={Multimedia Tools and Applications},volume={82},number={8},pages={11239--11264},year={2023},publisher={Springer},doi={10.1007/s11042-022-13557-w},url={https://link.springer.com/article/10.1007/s11042-022-13557-w},keywords={journal}}
Bimodal emotion recognition through audio-visual cues
Emotions play a crucial role in human-human communication with a complex socio-psychological nature, making emotion recognition a challenging task. In this dissertation, we study emotion recognition from audio and visual cues in video clips, utilizing facial expressions and speech signals, which are among the most prominent emotional expression channels. We propose novel computational methods to capture the complementary information provided by audio-visual cues for enhanced emotion recognition. The research in this dissertation shows how emotion recognition depends on emotion annotation, the perceived modalities, modalities’ robust data representations, and computational modeling. It presents progressive fusion techniques for audio-visual representations that are essential to improve their performance. Furthermore, the methods aim at exploiting the temporal dynamics of audio-visual cues and detect the informative time segments from both modalities. The dissertation presents meta-analysis studies and extensive evaluations for multimodal and temporal emotion recognition.
@phdthesis{ghaleb2021bimodal,author={Ghaleb, Esam},title={Bimodal emotion recognition through audio-visual cues},school={University of Somewhere},year={2021},url={https://cris.maastrichtuniversity.nl/en/publications/bimodal-emotion-recognition-through-audio-visual-cues}}
BNAIC20
Deep, dimensional and multimodal emotion recognition using attention mechanisms
Emotion recognition is an increasingly important sub-field in artificial intelligence (AI). Advances in this field could drastically change the way people interact with computers and allow for automation of tasks that currently require a lot of manual work. For example, registering the emotion a subject expresses for a potential advert. Previous work has shown that using multiple modalities, although challenging, is very beneficial. Affective cues in audio and video may not occur simultaneously, and the modalities do not always contribute equally to emotion. This work seeks to apply attention mechanisms to aid in the fusion of audio and video, for the purpose of emotion recognition using state-of-the-art techniques from artificial intelligence and, more specifically, deep neural networks. To achieve this, two forms of attention are used. Embedding attention applies attention on the input of a modalityspecific model, allowing recurrent networks to consider multiple input time steps. Bimodal attention fusion applies attention to fuse the output of modality-specific networks. Combining both these attention mechanisms yielded CCCs of 0.62 and 0.72 for arousal and valence respectively on the RECOLA dataset used in AVEC 2016. These results are competitive with the state-of-the-art, underlying the potential of attention mechanisms in multimodal fusion for behavioral signals.
@inproceedings{lucas2020deep,title={Deep, dimensional and multimodal emotion recognition using attention mechanisms},author={Lucas, Jan and Ghaleb, Esam and Asteriadis, Stylianos},booktitle={BNAIC/BeneLearn 2020},pages={130},year={2020},}
Multimodal Attention-Mechanism For Temporal Emotion Recognition
Esam Ghaleb, Jan Niehues, and Stylianos Asteriadis
In 2020 IEEE International Conference on Image Processing (ICIP) 2020
Exploiting the multimodal and temporal interaction between audio-visual channels is essential for automatic audio-video emotion recognition (AVER). Modalities’ strength in emotions and time-window of a video-clip could be further utilized through a weighting scheme such as attention mechanism to capture their complementary information. The attention mechanism is a powerful approach for sequence modeling, which can be employed to fuse audio-video cues overtime. We propose a novel framework which consists of biaudio-visual time-windows that span short video-clips labeled with discrete emotions. Attention is used to weigh these time windows for multimodal learning and fusion. Experimental results on two datasets show that the proposed methodology can achieve an enhanced multimodal emotion recognition.
@inproceedings{ghaleb2020multimodal,title={Multimodal Attention-Mechanism For Temporal Emotion Recognition},author={Ghaleb, Esam and Niehues, Jan and Asteriadis, Stylianos},booktitle={2020 IEEE International Conference on Image Processing (ICIP)},pages={251--255},year={2020},organization={IEEE},}
Temporal triplet mining for personality recognition
Dario Dotti, Esam Ghaleb, and Stylianos Asteriadis
In 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020) 2020
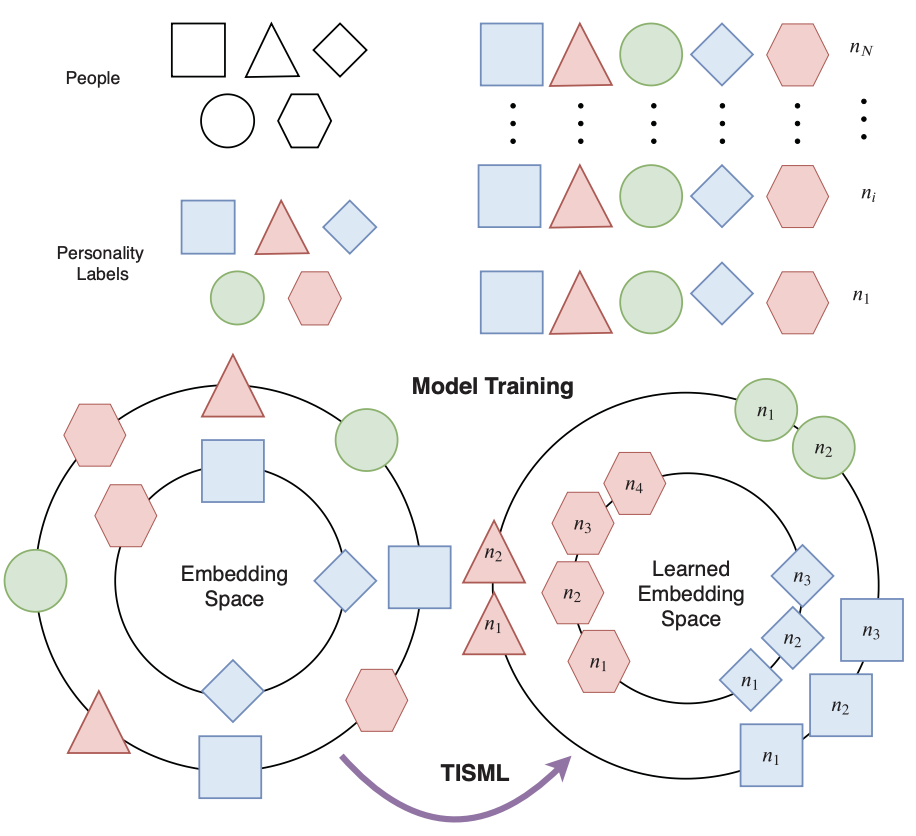
One of the primary goals of personality computing is to enhance the automatic understanding of human behavior, making use of various sensing technologies. Recent studies have started to correlate personality patterns described by psychologists with data findings, however, given the subtle delineations of human behaviors, results are specific to predefined contexts. In this paper, we propose a framework for automatic personality recognition that is able to embed different behavioral dynamics evoked by diverse real world scenarios. Specifically, motion features are designed to encode local motion dynamics from the human body, and interpersonal distance (proxemics) features are designed to encode global dynamics in the scene. By using a Convolutional Neural Network (CNN) architecture which utilizes a triplet loss deep metric learning, we learn temporal, as well as discriminative spatio-temporal streams of embeddings to represent patterns of personality behaviors. We experimentally show that the proposed Temporal Triplet Mining strategy leverages the similarity between temporally related samples and, therefore, helps to encode higher semantic movements or sub-movements which are easier to map onto personality labels. Our experiments show that the generated embeddings improve the state-of-the-art results of personality recognition on two public datasets, recorded in different scenarios.
@inproceedings{dotti2020temporal,title={Temporal triplet mining for personality recognition},author={Dotti, Dario and Ghaleb, Esam and Asteriadis, Stylianos},booktitle={2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020)},pages={379--386},year={2020},organization={IEEE},}
Multimodal and temporal perception of audio-visual cues for emotion recognition
Esam Ghaleb, Mirela Popa, and Stylianos Asteriadis
In 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) 2019
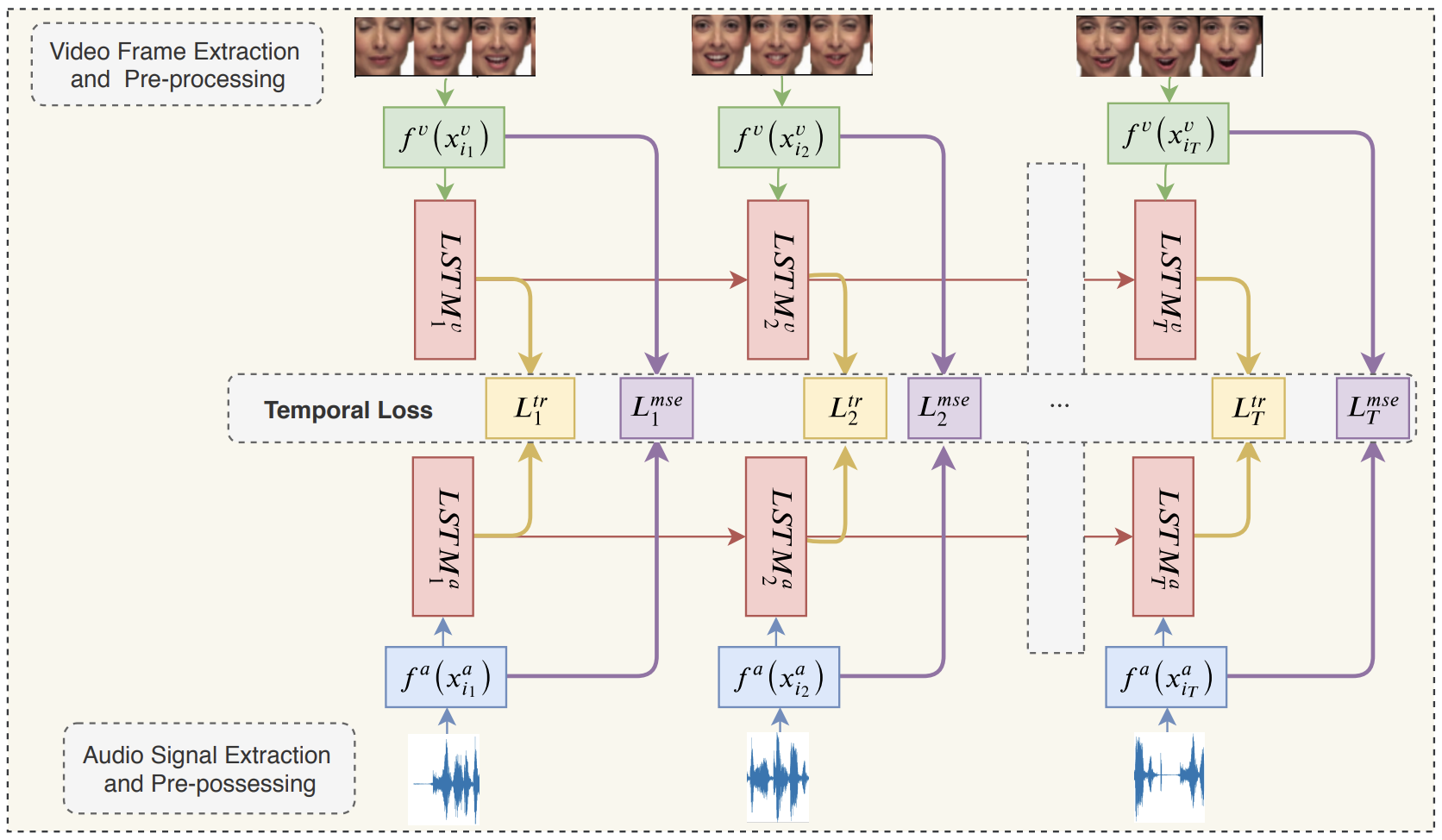
In Audio-Video Emotion Recognition (AVER), the idea is to have a human-level understanding of emotions from video clips. There is a need to bring these two modalities into a unified framework, to effectively learn multimodal fusion for AVER. In addition, literature studies lack in-depth analysis and utilization of how emotions vary as a function of time. Psychological and neurological studies show that negative and positive emotions are not recognized at the same speed. In this paper, we propose a novel multimodal temporal deep network framework that embeds video clips using their audio-visual content, onto a metric space, where their gap is reduced and their complementary and supplementary information is explored. We address two research questions, (1) how audio-visual cues contribute to emotion recognition and (2) how temporal information impacts the recognition rate and speed of emotions. The proposed method is evaluated on two datasets, CREMA-D and RAVDESS. The study findings are promising, achieving the state-of-the-art performance on both datasets, and showing a significant impact of multimodal and temporal emotion perception.
@inproceedings{ghaleb2019multimodal,title={Multimodal and temporal perception of audio-visual cues for emotion recognition},author={Ghaleb, Esam and Popa, Mirela and Asteriadis, Stylianos},booktitle={2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII)},pages={552--558},year={2019},organization={IEEE},}
Towards Affect Recognition through Interactions with Learning Materials
Esam Ghaleb, Mirela Popa, Enrique Hortal, and 2 more authors
In Machine Learning and Applications (ICMLA), 2018 17th International Conference on 2018
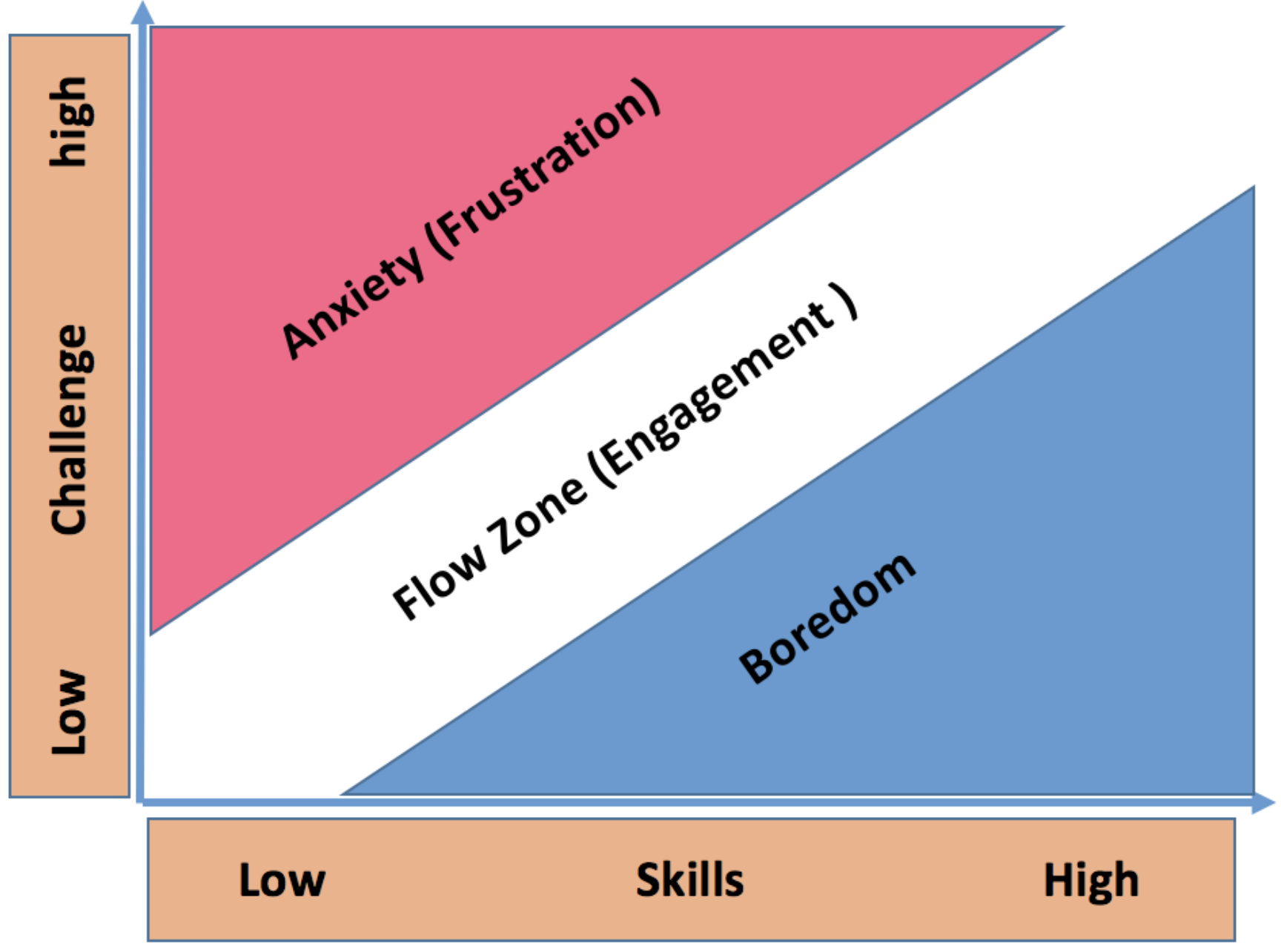
Affective state recognition has recently attracted a notable amount of attention in the research community, as it can be directly linked to a student’s performance during learning. Consequently, being able to retrieve the affect of a student can lead to more personalized education, targeting higher degrees of engagement and, thus, optimizing the learning experience and its outcomes. In this paper, we apply Machine Learning (ML) and present a novel approach for affect recognition in Technology-Enhanced Learning (TEL) by understanding learners’ experience through tracking their interactions with a serious game as a learning platform. We utilize a variety of interaction parameters to examine their potential to be used as an indicator of the learner’s affective state. Driven by the Theory of Flow model, we investigate the correspondence between the prediction of users’ self-reported affective states and the interaction features. Cross-subject evaluation using Support Vector Machines (SVMs) on a dataset of 32 participants interacting with the platform demonstrated that the proposed framework could achieve a significant precision in affect recognition. The subject-based evaluation highlighted the benefits of an adaptive personalized learning experience, contributing to achieving optimized levels of engagement.
@inproceedings{ghaleb2018towards,title={Towards Affect Recognition through Interactions with Learning Materials},author={Ghaleb, Esam and Popa, Mirela and Hortal, Enrique and Asteriadis, Stylianos and Weiss, Gerhard},booktitle={Machine Learning and Applications (ICMLA), 2018 17th International Conference on},pages={76--79},year={2018},organization={IEEE},}
Multimodal fusion based on information gain for emotion recognition in the wild
Esam Ghaleb, Mirela Popa, Enrique Hortal, and 1 more author
In Intelligent Systems Conference (IntelliSys), 2017 2017
@inproceedings{ghaleb2017multimodal,title={Multimodal fusion based on information gain for emotion recognition in the wild},author={Ghaleb, Esam and Popa, Mirela and Hortal, Enrique and Asteriadis, Stylianos},booktitle={Intelligent Systems Conference (IntelliSys), 2017},pages={814--823},year={2017},organization={IEEE},}
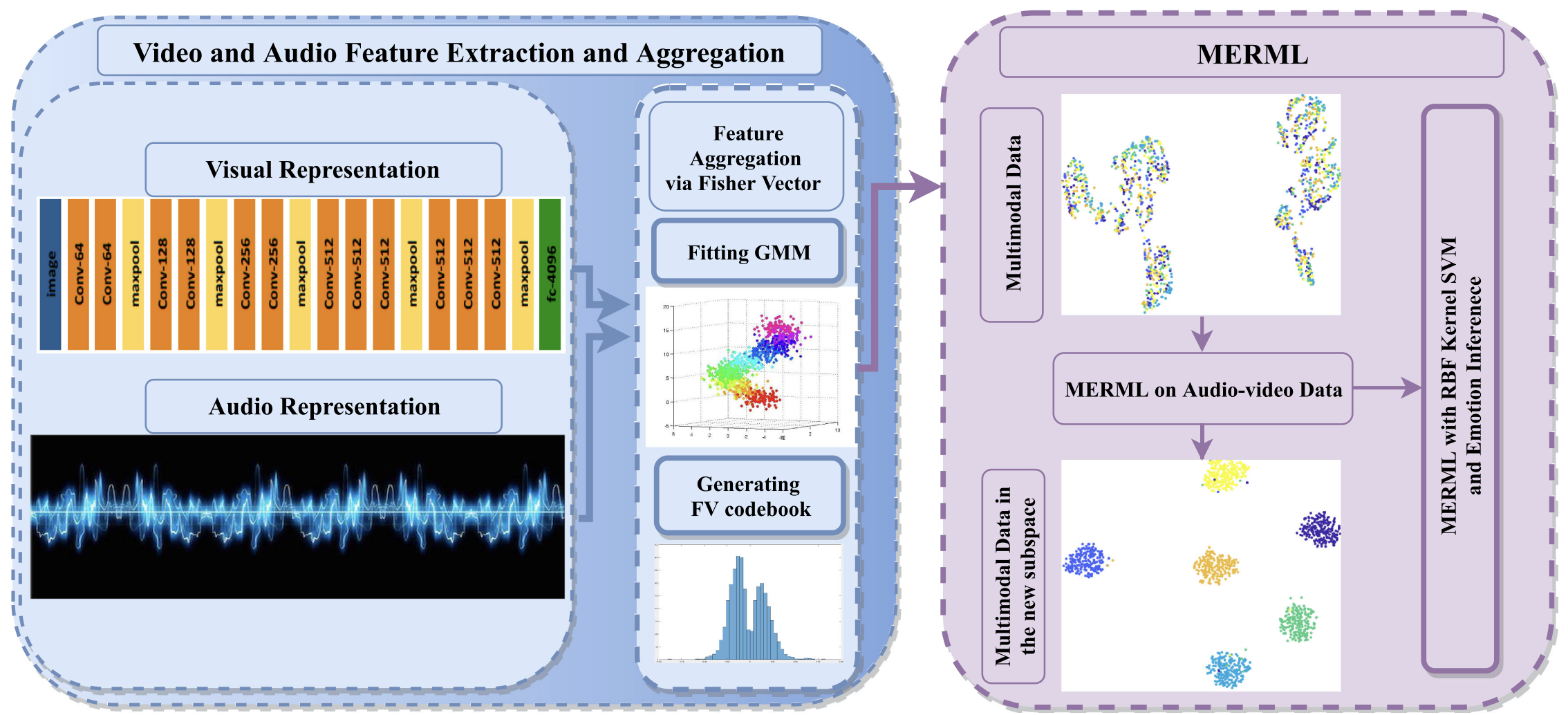
People express their emotions through multiple channels, such as visual and audio ones. Consequently, automatic emotion recognition can be significantly benefited by multimodal learning. Even-though each modality exhibits unique characteristics; multimodal learning takes advantage of the complementary information of diverse modalities when measuring the same instance, resulting in enhanced understanding of emotions. Yet, their dependencies and relations are not fully exploited in audio–video emotion recognition. Furthermore, learning an effective metric through multimodality is a crucial goal for many applications in machine learning. Therefore, in this article, we propose multimodal emotion recognition metric learning (MERML), learned jointly to obtain a discriminative score and a robust representation in a latent-space for both modalities. The learned metric is efficiently used through the radial basis function (RBF) based support vector machine (SVM) kernel. The evaluation of our framework shows a significant performance, improving the state-of-the-art results on the eNTERFACE and CREMA-D datasets.
@article{ghaleb2019metric,title={Metric learning-based multimodal audio-visual emotion recognition},author={Ghaleb, Esam and Popa, Mirela and Asteriadis, Stylianos},journal={Ieee Multimedia},volume={27},number={1},pages={37--48},year={2019},publisher={IEEE},keywords={journal},}

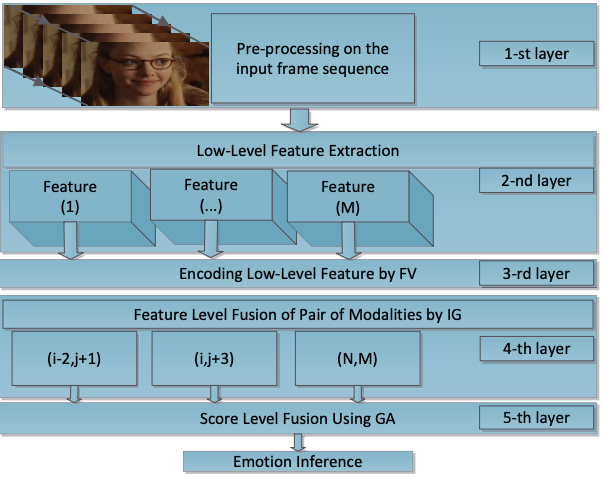 Multimodal fusion based on information gain for emotion recognition in the wildIn Intelligent Systems Conference (IntelliSys), 2017 2017
Multimodal fusion based on information gain for emotion recognition in the wildIn Intelligent Systems Conference (IntelliSys), 2017 2017